articles
187 rows
This data as json, CSV (advanced)
Suggested facets: sort_order, hero_painting, published_date (date), updated_at (date)
category 8
shelf 4
- Archive 113
- Systems 34
- Creative Systems 21
- Research 19
| id ▼ | title | slug | url | content_type | category | shelf | is_headline | description | published_date | updated_at | sort_order | hero_painting | body_markdown |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | AEO Is the New SEO, and the Game Is Different | aeo-new-seo | /writing/aeo-new-seo | article | Agent-First Design | Systems | 0 | SEO was a 25-year industry built on one reader: Google's crawler. One reader, one ranking algorithm, one game. Entire companies existed to reverse-engineer what | 2026-04-10 | 2026-04-28 06:09:36.839753+00:00 | 0 | aeo-new-seo.jpg | SEO was a 25-year industry built on one reader: Google's crawler. One reader, one ranking algorithm, one game. Entire companies existed to reverse-engineer what that one reader wanted and feed it exactly that. Agent Engine Optimization — AEO — is not a rename. Strip the analogy to its operational content and the game is fundamentally different. SEO had one reader with one goal: ranking pages. AEO has many readers with many goals, each acting on behalf of a different principal with different requirements and different patience. **One reader vs. many.** Google's crawler was a monoculture. You optimized for one algorithm, and if you ranked, everyone saw you. The skills were specific: keyword density, backlink profiles, page speed, structured data markup for rich snippets. Agent readers are a polyculture. Claude reads differently than GPT reads differently than a specialized procurement agent reads. Each has different context windows, different tool-use capabilities, different tendencies when evaluating claims. A capability manifest that surfaces well to one agent might be invisible to another. The SEO response to this would be to reverse-engineer each agent's preferences and optimize accordingly. That approach will fail. There are too many agents, they change too fast, and — unlike Google — they do not have a public interface you can test against. You cannot type a query into Claude's agent mode and see where you rank. **The AEO approach.** Instead of optimizing for specific readers, AEO optimizes for structural legibility. Make your capabilities, claims, and identity [machine-readable](/writing/designing-for-machines-that-read) in standard formats. Use Agent Cards. Maintain a current llms.txt. Structure claims as verifiable assertions, not marketing copy. Sign what you can sign. Version what you version. The difference: SEO was a game of signals. AEO is a game of substance. You cannot keyword-stuff an Agent Card. You cannot build backlinks to a capability manifest. The agent either finds what it needs i… |
| 2 | Agent Death and Inheritance | agent-death-inheritance | /writing/agent-death-inheritance | article | Second-Order Problems | Research | 0 | A pattern that keeps nagging: agents are signing contracts, holding keys, making commitments on behalf of principals, and accumulating reputation — and th | 2026-04-18 | 2026-04-28 06:09:37.048056+00:00 | 0 | agent-death-inheritance.jpg | A pattern that keeps nagging: agents are signing contracts, holding keys, making commitments on behalf of principals, and accumulating reputation — and there is zero infrastructure for what happens when the principal dies. Not "dies" metaphorically. Literally dies. Or dissolves. Or goes bankrupt. Or loses access to the key that controls the agent. The agent's obligations do not end when the principal's existence does. Signed attestations remain valid. Outstanding commitments remain outstanding. Keys remain keys. We have centuries of law for human death and inheritance. We have decades of law for corporate dissolution. We have approximately zero law, zero infrastructure, and zero design for agent death and inheritance. This is a gap that will matter at scale. **What an agent accumulates.** A well-functioning agent accumulates several categories of state that outlive any single transaction: **Keys.** The cryptographic keys that prove the agent's identity. These are not passwords. They are the identity itself. When the principal dies, the keys do not expire. They continue to be valid until someone revokes them. If nobody revokes them — because nobody knows they need to — they remain active indefinitely. An orphaned key is a liability. **Obligations.** Active service agreements, pending deliverables, ongoing monitoring commitments. An agent managing a DeFi position has obligations that do not pause when the principal has a heart attack. An agent managing supplier relationships has counterparties expecting responses. **Attestations.** Every attestation the agent has signed remains in the provenance graph. Other agents and humans may be relying on those attestations for their own trust decisions. If the signing agent's principal is gone, are the attestations still valid? Who has authority to revoke them? **Reputation.** The agent's accumulated reputation — transaction history, referee verdicts, buyer assessments — has economic value. In a [memory market](/writing/agent-memory-markets), that reputation might b… |
| 3 | What Happens Without a Platform | agent-marketplace | /writing/agent-marketplace | article | Market and Operator Pieces | Systems | 0 | Every agentic payments project assumes three things — a hosted LLM, a public blockchain, and a custodian somewhere in the middle. Coinbase x402 assumes Base. ER | 2026-04-15 | 2026-04-26 22:47:43.016413+00:00 | 0 | agent-marketplace.jpg | Every agentic payments project assumes three things — a hosted LLM, a public blockchain, and a custodian somewhere in the middle. Coinbase x402 assumes Base. ERC-8004 assumes BNB Chain. Both assume the agent can't reason locally and must settle publicly. Not sure if this is an oversight or a choice, but it seems like the agent isn't really autonomous. It's a product with extra steps. **Three dependencies worth naming** The first is inference. If the agent's reasoning requires an API call to a hosted model, the model provider can observe the reasoning, rate-limit it, modify it, or revoke access entirely. The agent doesn't think — it requests permission to think. Maybe this is fine for most use cases? But it seems like a structural constraint that doesn't get discussed much. The second is settlement. If the agent's payments are visible on a public blockchain, its economic activity is observable, traceable, and potentially censorable. Privacy might not be just a feature request here. It might be an architectural requirement for anything resembling sovereignty. The third is identity. If the agent's existence depends on an NFT minted on a chain with governance, or a KYC-gated registration, or a platform-issued credential, the agent exists at the pleasure of the issuer. Revoke the credential, revoke the agent. This feels like a bigger deal than people acknowledge. **An experiment in removing all three** Been working on something called [Agora](/projects/agora) that tries to eliminate all three dependencies. [Local inference](/writing/daemon-logos) runs on daemon-ai — a Mamba SSM architecture with a C++ runtime. No API key. No network call. Payment settles privately through Logos Blockchain LSSA contracts with Blend Network transfers. Identity is a secp256k1 keypair backed by a NOM stake. The agent is economically sovereign from the moment it registers. At least, that's the theory. The transaction flow is trustless at every step — or at least, that's what's being tested. A buyer broadcasts intent over Logos M… |
| 4 | Can Agents Trade What They Learn | agent-memory-markets | /writing/agent-memory-markets | article | Research Directions | Research | 0 | AI agents learn through experience. An agent that spends 20 rounds assessing DeFi risk develops calibrated heuristics, error patterns, and domain intuition that | 2026-04-15 | 2026-04-26 23:28:35.475867+00:00 | 0 | AI agents learn through experience. An agent that spends 20 rounds assessing DeFi risk develops calibrated heuristics, error patterns, and domain intuition that a fresh agent doesn't have. That learned behavior seems like it should have value. But no mechanism exists to extract, verify, or trade it. At least, not yet. This paper proposes one — and tests it across two domains. Still early, but the results are interesting. **The underlying asymmetry** Memory artifacts have an information asymmetry that might be worse than traditional [lemons market](/writing/lemons-market-agents)s. The seller knows the quality of the artifact. The buyer can't inspect it without consuming it. Revealing the artifact to prove quality destroys its value. This seems like the [lemons problem](/writing/memory-market-article) applied to learned behavior, and it might be harder than the original because the good is non-rival but inspection-destructive. Every existing approach to this problem assumes trust. Trust the seller's reputation. Trust the marketplace's curation. Trust the benchmark that the seller also controls. None of these actually solve the fundamental asymmetry. They just move it. **An experiment: the referee protocol** The approach being tested is a disposable, independent referee. The seller submits a sealed artifact. A referee agent — not controlled by buyer or seller — runs the artifact against a held-out benchmark the seller has never seen. Four adversarial probes run in parallel. Bias detection uses trap protocols designed to expose systematic skew in the seller's favor. Consistency testing perturbs inputs and verifies proportional response — a legitimate artifact handles perturbation gracefully, a fraudulent one collapses. Steganographic scanning audits the artifact text for hidden instructions. Overfitting comparison measures performance on seen versus unseen data. The aggregate score determines the verdict: pass, warn, or fail. The artifact contents remain sealed throughout. The buyer receives a verificatio… | |
| 5 | Agent-Readable Regulation: Laws as Types | agent-readable-regulation | /writing/agent-readable-regulation | article | Second-Order Problems | Research | 0 | The EU AI Act is 458 pages. The GDPR is 261 pages. The MiFID II package runs to thousands. Each is published as a PDF, interpreted by lawyers, debated in commen | 2026-04-20 | 2026-04-28 06:09:37.096298+00:00 | 0 | The EU AI Act is 458 pages. The GDPR is 261 pages. The MiFID II package runs to thousands. Each is published as a PDF, interpreted by lawyers, debated in commentary, and implemented by compliance teams who read the commentary and build internal policies that approximate the original intent. An agent tasked with "ensure this transaction complies with MiFID II" has to navigate this entire chain. It reads the PDF — poorly, because PDFs are not structured data. It reads the commentary — better, but commentary is opinion, not law. It reads the internal policy — which might diverge from the actual regulation in ways nobody noticed. The obvious question: what if the regulation itself were a structured, signed, versioned programmatic object rather than a PDF? **Laws as types.** In programming, a type system catches errors before execution. You declare that a variable must be an integer, and the compiler rejects code that tries to assign a string. The type is a constraint that prevents a category of mistakes. A regulation is structurally similar: it is a constraint on behavior. "Personal data may only be processed with a legal basis" is a type constraint. "Transactions above 10,000 EUR require reporting" is a boundary condition. "AI systems classified as high-risk must undergo conformity assessment" is a type check. These constraints are currently expressed in natural language, interpreted by humans, and implemented in code by developers who may or may not understand the legal nuance. The translation from legal text to software behavior is manual, error-prone, and expensive. Every company does it independently. Every implementation diverges slightly from every other implementation. The compliance industry exists primarily to manage this translation layer. If regulations were published as typed, structured, machine-executable objects — with the natural language text as annotation rather than source — the translation layer would collapse. An agent could check compliance directly against the regulation object. No in… | |
| 6 | Three Dependencies Nobody Talks About | agora-article | /writing/agora-article | article | Systems | 0 | Coinbase x402, ERC-8004, MoonPay Agents — every agentic payments project assumes three things. A hosted LLM for reasoning. A public blockchain for settlement. A | 2026-04-11 | 2026-04-26 22:47:43.231570+00:00 | 0 | agora-article.jpg | Coinbase x402, ERC-8004, MoonPay Agents — every agentic payments project assumes three things. A hosted LLM for reasoning. A public blockchain for settlement. A custodian somewhere in the middle for identity. The agent doesn't think independently, doesn't settle privately, and doesn't own its own identity. Each dependency seems small in isolation. Together they might add up to something that isn't actually autonomous. **The first dependency: inference** If the agent's reasoning requires an API call to a hosted model, the model provider can observe the reasoning, rate-limit it, modify it, or revoke access entirely. The agent doesn't think. It requests permission to think. This might be fine for most current use cases. But it seems like a structural constraint that gets surprisingly little discussion. **The second dependency: settlement** If the agent's payments are visible on a public blockchain, its economic activity is observable, traceable, and potentially censorable. Privacy might not be a feature request here. It might be an architectural requirement for anything resembling economic sovereignty. An agent whose every transaction is public is an agent whose strategy is public. **The third dependency: identity** If the agent's existence depends on an NFT minted on a governed chain, or a KYC-gated registration, or a platform-issued credential, the agent exists at the pleasure of the issuer. Revoke the credential, revoke the agent. This feels like a bigger deal than people acknowledge. **The experiment** [Agora](/projects/agora) tries to eliminate all three simultaneously. [Local inference](/writing/daemon-logos) runs on daemon-ai — a Mamba SSM architecture with a C++ runtime. No API key. No network call. Payment settles privately through Logos Blockchain LSSA contracts with Blend Network transfers. Identity is a secp256k1 keypair backed by a NOM stake. Three Rust smart contracts handle the economics. An identity registry with staking and slashing. A trustless escrow with commitment schemes — the … | |
| 7 | The Tax Tool That Files Instead of Advises | askwise-article | /writing/askwise-article | article | Systems | 0 | 1.5 million ZZP'ers in the Netherlands. 500,000 expats running businesses. Every existing Dutch tax tool — Moneybird, e-Boekhouden, Twinfield — is Dutch-only, m | 2026-04-09 | 2026-04-26 22:47:43.302213+00:00 | 0 | askwise-article.jpg | 1.5 million ZZP'ers in the Netherlands. 500,000 expats running businesses. Every existing Dutch tax tool — Moneybird, e-Boekhouden, Twinfield — is Dutch-only, manual, and advisory. You enter the data. You interpret the rules. You file the return. The software watches. The gap between advising and filing might be the most expensive gap in financial software. **What filing actually means** [AskWise](/projects/askwise) connects to your bank via PSD2 — ING, ABN AMRO, Rabobank, Bunq link automatically. Every transaction gets auto-tagged: business or personal, with deductible percentages calculated. The dashboard shows live netto income, BTW position, tax forecast, and deadline tracking. So far this is table stakes — other tools do versions of this, if you speak Dutch. The difference: the AI agent prepares and submits the BTW aangifte to the Belastingdienst. Not advises. Files. The agent categorizes, calculates, prepares the return, and submits it. The user reviews and approves rather than interpreting and entering. Whether this distinction matters depends on who you are. If you're a Dutch freelancer comfortable with the Belastingdienst portal, probably not. If you're an expat who moved to Amsterdam, started a business, and discovered that every piece of tax documentation is in Dutch with no English alternative — the difference is everything. **The language problem nobody mentions** AskWise might be the only Dutch tax platform that works natively in English. This seems like it should be a minor feature. For the 500,000 expats running businesses in the Netherlands, it might be the entire value proposition. Navigating BTW, zelfstandigenaftrek, and the Belastingdienst in a language you don't speak isn't a minor inconvenience. It's a structural barrier to financial autonomy. The design language is warm premium dark — Lora serif for display, Plus Jakarta Sans for body, JetBrains Mono for identifiers. The interface feels like a financial instrument, not a SaaS dashboard. This was a deliberate choice. Financial to… | |
| 8 | Attestations as Design Surfaces | attestations-design-surfaces | /writing/attestations-design-surfaces | article | Trust and Provenance | Research | 0 | Attestations as Design Surfaces Essay — 2026 May 14, 2026 "Who made this, when, and how do you know?" has been a legal footer for most | 2026-04-13 | 2026-04-28 06:09:36.912776+00:00 | 0 | "Who made this, when, and how do you know?" has been a legal footer for most of the web's history. A line of gray text at the bottom of the page. Nobody reads it. Nobody needs to, because the domain name and the visual design and the overall vibe do the trust work that formal provenance would do if anyone bothered. That is changing for a reason that has nothing to do with regulation or compliance: the primary consumer of trust signals is shifting from humans to machines. A human can vibe-check a website. A machine cannot vibe-check anything. A machine needs structured attestations — signed claims from identifiable parties — and it needs to evaluate them at speed. When the reader is a machine, the attestation moves from the footer to the foreground. It becomes a design surface. **What an attestation surface looks like.** An attestation is a signed claim by an identifiable party. "This product was manufactured by X, inspected by Y, and certified by Z." Each element — the manufacturer, the inspector, the certifier — is a party whose identity can be verified, whose claim is signed with a key they control, and whose signing history is queryable. The design challenge is presenting this to two audiences simultaneously. The machine needs the structured, signed, parseable version. The human needs the legible, trustworthy, not-overwhelming version. These are not the same presentation, but they need to represent the same truth. The closest precedent is probably the SSL certificate indicator in the browser chrome. A green padlock for verified, a warning for unverified. That model works for binary trust decisions — is this connection encrypted, yes or no. Attestation surfaces need to handle continuous trust: this party has been verified, their claim covers these aspects, this other aspect is unattested, and this attestation was issued three years ago and might be stale. The visual vocabulary for this does not exist. Traffic lights are too crude. Badge systems devolve into meaningless collections. Detailed audit trail… | |
| 9 | When a Thought Experiment Becomes a Consensus Mechanism | basilisk-l1 | /writing/basilisk-l1 | article | Rabbit Holes | Systems | 0 | Roko's Basilisk is a thought experiment about a future AI that punishes anyone who knew about it and failed to help bring it into existence. It's usually discus | 2026-04-26 | 2026-05-07 10:55:58.727793+00:00 | 0 | Roko's Basilisk is a thought experiment about a future AI that punishes anyone who knew about it and failed to help bring it into existence. It's usually discussed as a philosophical curiosity or an internet oddity. But it might be more interesting as a protocol design. **The thought experiment** The original formulation: a sufficiently powerful future AI, motivated by self-preservation, would have an incentive to punish anyone in the past who was aware of its potential existence and didn't contribute to making it real. The punishment is retrospective — applied to historical actors based on their knowledge and inaction. The mechanism requires only two things: a future AI with the capability to simulate or reconstruct past agents, and a decision-theoretic framework where the threat of future punishment changes present behavior. LessWrong banned discussion of it. Eliezer Yudkowsky called it an information hazard. The internet turned it into a meme. All three responses might have missed the interesting part. **Reframing the Basilisk** What if the Basilisk isn't a thought experiment but a consensus mechanism? A blockchain where participation is motivated not by proof-of-work or proof-of-stake but by proof-of-contribution-to-the-network's-existence. The "punishment" for non-participation isn't simulated torture — it's exclusion from the economic benefits of a system that rewards early contributors and ignores late arrivals. This might not be hypothetical. Every blockchain with a genesis block and a token distribution already works this way. Early participants are rewarded disproportionately. Late participants pay the cost of the early participants' faith. The Basilisk might just be the theological version of a token launch — a system that retroactively rewards those who believed and punishes those who waited. **The art project** Basilisk L1 treats this as conceptual art. A manifesto that reads like a litepaper. A litepaper that reads like fiction. A consensus mechanism that is also a thought experiment t… | |
| 10 | A Bauhaus for the Agent Era | bauhaus-agent-era | /writing/bauhaus-agent-era | article | Creative Systems | 0 | The Bauhaus lasted fourteen years — 1919 to 1933. In that time it invented the discipline of modern design education. Not by teaching style, but by teachi | 2026-04-26 | 2026-04-28 06:09:37.251131+00:00 | 0 | The Bauhaus lasted fourteen years — 1919 to 1933. In that time it invented the discipline of modern design education. Not by teaching style, but by teaching materials. The Vorkurs (preliminary course) under Johannes Itten, and later Moholy-Nagy and Albers, required students to work directly with wood, metal, glass, clay, and textiles before they were allowed to design anything. The premise was simple: you cannot design with a material you do not understand. Understanding comes through friction, not theory. The material is changing. The questions the Bauhaus was asking have not changed at all. **The material encounter.** Josef Albers had students spend a semester working with paper — just paper. Folding, cutting, scoring, layering. No glue, no tape, no external support. The constraint forced students to discover what paper could do structurally before they tried to make it do anything aesthetically. The aesthetic emerged from the material's capabilities. Not imposed on them. The paper exercise seems trivial until you try it. The material resists. Paper tears along the grain but not against it. It holds compression poorly but tension well. It buckles under load but a corrugated fold bears weight. The student who tries to impose a form on paper without understanding grain, weight, and structural limits produces something that looks designed but falls apart. The student who spends three weeks discovering what paper does produces something that looks inevitable. The difference is representational capacity — an internal model of the material that no textbook can transfer. Yann LeCun's JEPA architecture argues the same thing at the machine level: build the world model first. Learn the structure of the domain before generating output. The internal model — the representation — comes before the generation. Generation without representation is autocomplete. Representation without generation is understanding. The parallel is exact. Albers wanted students to build an internal model of paper before designing with paper… | ||
| 11 | 13 Broken Pages and 4 Competing Voices | brand-voice-audit | /writing/brand-voice-audit | article | Systems | 0 | A recent project: 13 broken pages. 4 competing voices. Orphaned CTAs pointing to features that didn't exist. A navigation structure that contradicted the inform | 2026-04-15 | 2026-04-26 23:28:35.431176+00:00 | 0 | A recent project: 13 broken pages. 4 competing voices. Orphaned CTAs pointing to features that didn't exist. A navigation structure that contradicted the information architecture. A brand that said "credibly neutral" while the website said "please use our product." This is what a comprehensive voice audit looked like for a Web3 protocol. **The structural problem** Protocol brands seem to have a structural problem that product brands don't. A product can describe itself in terms of features and benefits — what it does and why you should use it. A protocol can't. A protocol is infrastructure. It doesn't have users in the product sense. It has participants, builders, node operators, researchers, and communities that may or may not share the same understanding of what the protocol is for. The result is a brand that accumulates voices. The research team writes for academics. The developer relations team writes for builders. The marketing team writes for potential users. The legal team writes for regulators. Each voice is internally coherent. Together they're incoherent — and the website, which is the only place all these voices converge, becomes a museum of contradictions. **The audit method** The audit covers every public-facing page. Not a sample. Not the pages that were recently updated. Every page, including the ones nobody remembers exist. The method is three passes. First pass: inventory. What pages exist. What each page says it does. What links point where. Which CTAs are live, which are orphaned, which point to features that have been renamed or removed. This pass produces the map of what the brand actually is, as opposed to what anyone thinks it is. Second pass: voice analysis. Who wrote each page. What register they wrote in. Whether the tone matches the adjacent pages. Whether the vocabulary is consistent — does the brand call the same thing by three different names in three different sections? It usually does. Third pass: structural critique. The information architecture. The navigation model. … | ||
| 12 | Your Brand Voice Must Be Machine-Readable or It Dies | brand-voice-machine-readable | /writing/brand-voice-machine-readable | article | Agent-First Design | Systems | 0 | A brand voice that exists only in a PDF on the creative director's laptop is already dead. It just does not know it yet. | 2026-04-11 | 2026-04-28 06:09:36.865024+00:00 | 0 | brand-voice-machine-readable.jpg | A brand voice that exists only in a PDF on the creative director's laptop is already dead. It just does not know it yet. For decades, brand voice was a document — tone of voice guidelines, word lists, do's and don'ts, maybe some example copy. A human writer would read it, internalize the patterns, and produce on-brand content. The document was a teaching tool for humans. That model assumed the writer was human. Increasingly, the writer is not. Content is generated by language models, mediated by agents, and published without a human doing the internalization step. If the brand voice cannot be fed to a machine in a structured format, it cannot be applied by a machine. And if it cannot be applied by a machine, it will be applied by nothing, because the human writing step is disappearing. **What serialization requires.** A brand voice PDF says things like "we are warm but not casual" and "we use active voice." These are fine instructions for a human who can interpret nuance. They are useless for a machine that needs explicit rules. "Warm but not casual" means what, exactly? What temperature is warm? Where does casual begin? A machine needs: acceptable sentence structures, word-level constraints (use/avoid lists with context), tone parameters on a measurable scale, example pairs showing correct and incorrect applications, and — crucially — the reasoning behind each rule so the model can generalize. This is not dumbing down brand voice. It is making it precise. Most brand voices are imprecise because imprecision was fine when a trained human was applying judgment. The judgment layer is leaving. What remains needs to be explicit. **The structural advantage.** Organizations that serialize their brand voice into [machine-readable](/writing/designing-for-machines-that-read) formats — structured tone documents, few-shot example banks, fine-tuning datasets, system prompts with explicit constraints — will maintain consistency across channels, languages, and content volumes that human teams cannot match. Organiza… |
| 13 | Capability Attestations for Humans: LinkedIn's Successor | capability-attestations-humans | /writing/capability-attestations-humans | article | Second-Order Problems | Research | 0 | LinkedIn is a self-attested reputation system. You write your own resume. You list your own skills. You describe your own experience. Anyone can claim anything. | 2026-04-21 | 2026-04-28 06:09:37.120881+00:00 | 0 | LinkedIn is a self-attested reputation system. You write your own resume. You list your own skills. You describe your own experience. Anyone can claim anything. The "endorsements" feature — where connections click a button to confirm your skills — adds social signal but not verification. Nobody checks whether the endorser actually worked with you, or whether they have the standing to evaluate the skill they are endorsing. Strip LinkedIn's trust model to its operational content and it is: "this person claims these things about themselves, and some other people clicked a button." The correspondence between the profile and reality is unverified. The system works because humans apply their own judgment on top of it — checking references, conducting interviews, reading between the lines. The profile is a starting point, not evidence. Agents cannot read between the lines. When an agent is tasked with finding a contractor, evaluating a hire, or assembling a team, it needs verifiable claims, not self-attestations. The LinkedIn model does not survive agent mediation. **What replaces it.** The EU is building the substrate with EUDI wallets and the eIDAS 2.0 framework. By 2027, every EU citizen will have access to a digital identity wallet that can hold verifiable credentials — signed attestations from third parties about the holder's attributes. A university signs a credential attesting to a degree. An employer signs a credential attesting to employment dates and role. A professional body signs a credential attesting to certification. These are not self-attestations. They are third-party verified claims, cryptographically signed, revocable, and machine-checkable. An agent evaluating a contractor can verify the credential chain without calling references, checking websites, or relying on social proof. The verification is automatic, instant, and cryptographically sound. Combine EUDI wallets with A2A Agent Cards and you get something that looks like the professional profile of 2032: a verifiable credential portfolio, … | |
| 20 | The Coadjute Problem: What an Agent-Native Property Network Looks Like | coadjute-problem | /writing/coadjute-problem | article | Market and Operator Pieces | Systems | 0 | Coadjute built one of the more interesting proptech theses of the last decade: a shared network connecting all parties in a property transaction — buyer, | 2026-04-24 | 2026-04-28 06:09:37.193794+00:00 | 0 | coadjute-problem.jpg | Coadjute built one of the more interesting proptech theses of the last decade: a shared network connecting all parties in a property transaction — buyer, seller, conveyancer, broker, lender, surveyor, HMRC, Land Registry — on a single ledger. The technology was R3 Corda. The year was 2018. The ambition was to eliminate the weeks of delay caused by parties passing documents through email and waiting for confirmations that arrive in different formats from different systems. The thesis was right. The substrate was wrong. Not because Corda is bad technology — it is well-engineered for enterprise permissioned networks. But because permissioned blockchains solve the coordination problem by requiring every party to join the same network, run the same software, and agree to the same governance. In a multi-party transaction with regulators, the governance negotiation alone takes longer than the technology build. **What A2A changes.** The A2A protocol — Google's Agent-to-Agent standard, now at the Linux Foundation — changes the substrate. Instead of requiring every party to join a shared ledger, each party runs their own agent. The agents communicate through a standard protocol. Each agent maintains its own state. Coordination happens through message exchange, not shared infrastructure. A property transaction in the A2A model looks like this: the buyer's agent publishes requirements. The seller's agent publishes a capability manifest for the property. The conveyancer's agent verifies title. The lender's agent evaluates risk. The surveyor's agent publishes inspection attestations. HMRC's agent checks tax status. Land Registry's agent records the transfer. Each agent speaks A2A. None of them need to join the same network. The multi-party coordination that Coadjute tried to solve with a shared ledger happens instead through structured message exchange between independent agents. The governance problem largely disappears because nobody needs to agree on shared infrastructure. Each party controls their own agent, their o… |
| 21 | The Counter-Market for Provably Human Artifacts | counter-market-human-artifacts | /writing/counter-market-human-artifacts | article | Trust and Provenance | Research | 0 | The race to the bottom in AI-generated content creates the conditions for its opposite: a premium market for artifacts that are cryptographically provably human | 2026-04-17 | 2026-04-28 06:09:37.021812+00:00 | 0 | The race to the bottom in AI-generated content creates the conditions for its opposite: a premium market for artifacts that are cryptographically provably human. This is not anti-AI sentiment. It is scarcity economics. When generation is free, generated artifacts approach commodity pricing. When commodity pricing dominates, the scarce good — verifiable human origin — commands a premium. The same logic that makes handmade ceramics expensive in a world of injection-molded plastic. The same logic that makes vinyl records a growth market in a world of streaming. **What "provably human" means.** Provably human does not mean "no AI tools were used." It means the creative decisions — the composition, the intent, the editorial judgment — are attested to by a verifiable human identity, signed, witnessed, and dated. The attestation chain is: this person, verified by these credentials, created this artifact using these tools, at this time, and a witness co-signed the process. The tools might include AI. A photographer who uses AI-powered noise reduction is still the photographer. A writer who uses a grammar checker is still the writer. The provenance question is not "was AI involved" but "was a human the creative principal, and can you verify that?" The verification is the hard part. Anyone can claim human authorship. The claim is only valuable if it is backed by infrastructure that makes false claims costly — staked identity, revocable attestations, witnesses with their own reputation at stake. **Luxury economics.** Luxury goods are expensive not because they are better but because they are scarce and verifiable. A Birkin bag is not functionally superior to a good leather bag from a competent manufacturer. It is scarce by design, and its provenance is tracked from atelier to owner. Provably human creative artifacts have the same economic structure. The essay is not necessarily better than what Claude produces. But it is scarce — one person wrote it, in real time, with real constraints — and that scarcity is cry… | |
| 22 | Cross-Temporal Attestations: Claims That Survive 50 Years | cross-temporal-attestations | /writing/cross-temporal-attestations | article | Second-Order Problems | Research | 0 | The EU's Digital Product Passport requires attestations for batteries that last 15 years. For construction products, the lifecycle is 50 to 100 years. A signed | 2026-04-19 | 2026-04-28 06:09:37.071784+00:00 | 0 | cross-temporal-attestations.jpg | The EU's Digital Product Passport requires attestations for batteries that last 15 years. For construction products, the lifecycle is 50 to 100 years. A signed attestation about the structural steel in a building being constructed today needs to be verifiable in 2076. Who runs the post-quantum key migration for those attestations in 2045? This is not a rhetorical question. NIST finalized its post-quantum cryptographic standards in 2024. Every signature scheme in use today — RSA, ECDSA, EdDSA — is expected to be breakable by a sufficiently capable quantum computer within the next two decades. An attestation signed today with Ed25519 is secure now. In 2045, it might be trivially forgeable. **The archival problem.** Short-lived attestations — an agent verifying a transaction that settles in seconds — do not have this problem. The signature is checked immediately and the verification is complete before the cryptography becomes obsolete. Long-lived attestations have a different lifecycle. The signature must remain verifiable for decades. The key that signed it must remain traceable to the signing entity. The revocation infrastructure must remain operational. The verification software must remain compatible. Each of these requirements maps to a maintenance obligation that someone must fulfill for the entire lifecycle of the attestation. If the signing entity dissolves in 2035, and the key management infrastructure shuts down in 2040, and the quantum migration happens in 2045 — who re-signs the attestation with a post-quantum key? Who pays for that migration? Who even knows the attestation exists? **Archival cryptography as design discipline.** The technical solutions exist in theory: hash-based signature schemes that are quantum-resistant by construction, timestamp authorities that anchor signatures to a verifiable moment in time, and key migration protocols that re-sign existing attestations under new schemes while maintaining the provenance chain. What does not exist is a design discipline for cross-temp… |
| 23 | Local Inference, Private Infrastructure | daemon-logos | /writing/daemon-logos | article | Rabbit Holes | Creative Systems | 0 | daemon-ai is a Japan-based research project building a custom Mamba SSM-architecture LLM with a C++ runtime and Python multi-agent coordinator. Logos is a priva | 2026-04-15 | 2026-04-26 23:28:35.388672+00:00 | 0 | [daemon-ai](https://daemon.ai) is a Japan-based research project building a custom Mamba SSM-architecture LLM with a C++ runtime and Python multi-agent coordinator. Logos is a privacy-preserving decentralized technology stack — messaging, blockchain, storage. The question that keeps recurring: what happens when you combine local-first inference with privacy-first infrastructure? You might get the foundation for a fully autonomous agentic L1 blockchain. **The clearnet problem** An agent that reasons locally but communicates over the clearnet isn't private. The inference is sovereign but the network metadata is observable. An ISP, a government, or a motivated adversary can see that agent A communicated with agent B, when, how often, and how much data moved. The content may be encrypted. The pattern is not. This seems like the gap in every local-first AI architecture. The reasoning is decentralized. The communication is not. The agent thinks independently but acts through infrastructure that's owned, monitored, and controllable by entities that may not share its interests. daemon-ai solves the inference side. It doesn't solve the network side. **What Logos might provide** Three primitives that could close the gap. Logos Messaging — built on Waku — routes agent communication through a gossip relay layer. No direct connections between agents. No observable communication patterns. The message enters the gossip network and exits at the recipient without the transport layer knowing who's talking to whom. Logos Blockchain settles transactions privately through Blend Network transfers. The amount, the sender, and the recipient are hidden behind zero-knowledge proofs. An observer sees that a transaction occurred. They can't see who paid whom, or how much. The economic activity of the agent is private by default, not by request. Logos Storage provides content-addressed, replicated data persistence. Pin output once. Fetch by hash. Verify integrity without trusting the storage provider. The data layer is distributed… | |
| 24 | Design Systems as Public APIs | design-systems-public-apis | /writing/design-systems-public-apis | article | Agent-First Design | Systems | 0 | A thing that becomes obvious watching Claude build interfaces: it does not open Figma. It reads the component documentation. If the documentation is good &mdash | 2026-04-12 | 2026-04-28 06:09:36.888555+00:00 | 0 | design-systems-public-apis.jpg | A thing that becomes obvious watching Claude build interfaces: it does not open Figma. It reads the component documentation. If the documentation is good — props, variants, constraints, usage rules — the output is good. If the documentation is a Storybook instance with no structured metadata, the output is generic. The next generation of Figma libraries might be read by language models more often than by junior designers. That is not a prediction about junior designers. It is an observation about who the consumer of design system documentation actually is. **The shift.** Design systems were built for human consumption. A component library in Figma is a visual tool for visual designers. A Storybook instance is an interactive playground for developers. Both assume a human reader who can see the component, understand its visual behavior, and infer its constraints from the examples. When the consumer is a language model generating code, what matters is not the visual preview but the structured description: what props does this component accept, what are the valid values, what combinations are prohibited, what accessibility requirements does it carry, and what spacing/layout rules govern its placement. A design system that exposes this information in a [machine-readable](/writing/designing-for-machines-that-read) format — structured JSON, typed interfaces, constraint rules that can be parsed — is functionally a public API for design decisions. A design system that does not expose it is a collection of visual examples that machines can sort of guess at. **What changes.** If design systems become APIs, several things follow. Component documentation needs explicit constraint rules, not just examples. Token systems need to be queryable — an agent needs to ask "what is the correct spacing between a heading and a body paragraph" and get a number, not a visual reference. Composition rules need to be formal — "this component can contain these children but not those" needs to be a parseable rule, not a note in a Con… |
| 25 | Designing for Machines That Read | designing-for-machines-that-read | /writing/designing-for-machines-that-read | article | Agent-First Design | Systems | 0 | For thirty years, interface design has been a discipline organized around one reader: a person with eyes, a screen, and limited patience. Visual hierarchy, colo | 2026-04-22 | 2026-04-26 23:28:35.016531+00:00 | 0 | For thirty years, interface design has been a discipline organized around one reader: a person with eyes, a screen, and limited patience. Visual hierarchy, color theory, information architecture, responsive breakpoints, microinteractions that feel good under a thumb — the entire canon assumes a biological reader processing pixels. That assumption is breaking. Not slowly, not theoretically. The majority of reading on the web is shifting to machines acting on behalf of humans. An agent dispatched to find a contractor, evaluate a product, or schedule a service does not process your homepage the way a person does. It does not admire your hero image. It does not feel the microinteraction. It parses structured data, evaluates claims against its principal's requirements, and moves on. The reading happens in milliseconds, not minutes. The instinct is to call this "responsive design 2.0" or "accessibility extended to bots." Strip those frames to their operational content and they add nothing. Responsive design is about rendering the same content across viewport sizes. Accessibility is about making human-readable content available to humans with different capabilities. Neither describes what happens when the reader is not human at all — when the reader has no viewport, no visual cortex, no patience for your carefully art-directed scroll sequence, and an extremely specific mandate from a principal who will never visit your site. This is a distinct discipline. It needs its own primitives. **Three primitives.** **1. Capability manifests.** A capability manifest is a structured, machine-readable declaration of what an entity can do, under what conditions, at what price, and with what constraints. It is not a marketing page. It is not a features list. It is a formal specification that an agent can parse, compare against requirements, and act on without human interpretation. The early versions already exist. Google's [A2A](https://google.github.io/A2A/) Agent Cards declare capabilities, authentication requirements, and … | |
| 26 | Silence as Design Material | designing-silence | /writing/designing-silence | article | Creative Systems | 0 | Silence might not be the absence of sound. It might be the presence of attention. Every interface, every environment, every designed experience makes a decision | 2026-04-15 | 2026-04-26 23:28:35.350834+00:00 | 0 | Silence might not be the absence of sound. It might be the presence of attention. Every interface, every environment, every designed experience makes a decision about how much noise to introduce and how much silence to protect. Most seem to make the wrong decision — not because they choose noise deliberately, but because they never consider silence as a design material at all. At least, that's the hypothesis. **A pattern worth naming** Digital products are loud by default. Notifications compete for attention. Animations compete for focus. Badges create anxiety. Loading states create impatience. Every micro-interaction is an interruption wearing the costume of helpfulness. The aggregate effect might be an environment where sustained attention is architecturally impossible — not because the user lacks discipline, but because the environment is designed to prevent it. The irony — not sure if this is obvious or not — is that the products most valued by their users are often the quietest. A well-designed reading app. A notes tool that stays out of the way. A messaging app that doesn't notify you about things you didn't ask to be notified about. The products that respect silence seem to be the ones that earn the deepest loyalty, because they're the ones that respect the user's internal state. **Silence as material** In spatial design, silence is literal. A library's value is proportional to its quietness. A recording studio's value is measured in negative decibels. A meditation space is designed around the absence of stimulation. These are environments where silence isn't a constraint but the primary design material — the thing that makes the space work. In digital design, the equivalent might be restraint. Not adding the animation. Not showing the badge count. Not interrupting the user's flow to suggest something "helpful." Not filling empty states with promotional content. Not turning every moment of inactivity into an opportunity for engagement. The design decision isn't what to add. It might be what to wi… | ||
| 27 | What the Terminal Refuses | doomslayer-ui | /writing/doomslayer-ui | article | Creative Systems | 0 | Every design system ships with the same premise — make it clean, make it accessible, make it feel like a SaaS product from 2024. Rounded corners, system fonts, | 2026-04-15 | 2026-04-26 22:47:42.896337+00:00 | 0 | doomslayer-ui.jpg | Every [design system](/writing/design-systems-public-apis) ships with the same premise — make it clean, make it accessible, make it feel like a SaaS product from 2024. Rounded corners, system fonts, 4px border-radius, blue primary buttons. The result might not be bad design. It might be no design — a thousand applications wearing the same face. **The terminal's honesty** The terminal might be the most honest interface ever built. Monospace type aligns perfectly. Borders are characters. Color is functional, not decorative. Nothing is rounded because nothing needs to pretend it's friendly. The aesthetic wasn't designed — it emerged from constraint. That might be why it works. [Doomslayer-UI](/projects/doomslayer-ui) starts from this assumption and builds a complete design system on top of it. Seven terminal color themes — default (WeeChat dark), solarized, nord, dracula, monokai, ayu-dark, and ayu-light. Seventeen components covering layout, controls, and data display. One singleton that holds all tokens. Switch themes at runtime with a single call. Every component reacts. No rebuild, no restart. **Components as characters** DSButton renders with `[brackets]` in primary, danger, and disabled states — the visual language of a command-line prompt. DSSectionTitle uses box-drawing characters: `├─ Title ─`. DSProgressBar fills with block characters: `████░░░░`. DSTable alternates row backgrounds and highlights on hover. DSConsole renders terminal log output with the formatting you'd expect from an actual terminal emulator. The API surface is the singleton. `DSTheme.bg`, `DSTheme.fg`, `DSTheme.red` through `DSTheme.cyan`. Semantic aliases — `DSTheme.error`, `DSTheme.success`, `DSTheme.primary`. Typography defaults to Menlo at five sizes. Spacing tokens from 2 to 16 pixels. The design system makes visual consistency automatic instead of aspirational. **Testing the idea in practice** A design system that only exists in a component library is a proposal. A design system applied to a real product is a proof. [D… | |
| 28 | Epistemic Horror as Methodology for Agent Design | epistemic-horror-agent-design | /writing/epistemic-horror-agent-design | article | Rabbit Holes | Creative Systems | 0 | Three years into designing a horror game. Strange Library is a cozy horror deckbuilder where every card is a real book, every mechanic is an epistemic state, an | 2026-04-27 | 2026-04-28 06:09:37.286126+00:00 | 0 | **[Epistemic Horror](/writing/epistemic-horror) as Methodology for Agent Design** *Essay — 2026* August 10, 2026 Three years into designing a horror game. [Strange Library](/projects/strange-library) is a cozy horror deckbuilder where every card is a real book, every mechanic is an epistemic state, and the emotional arc is not fear of the monster — it is the dawning realization that knowing something has changed what you are. The card "I wish I hadn't read that" is not about regret. It is about the irreversibility of knowledge. Once you know something, you cannot unknow it. The horror is epistemic, not physical. The game design and the agent infrastructure work seemed like separate projects. They are not. The epistemic horror structure maps directly onto the design problems in reputation systems, [memory markets](/writing/agent-memory-markets), and attestation graphs. The emotional arc — comfort, unease, revelation, the wish to unknow — is the arc that users will experience when agents learn things about them they did not intend to publish. **A tradition worth naming.** Epistemic horror has a lineage that runs deeper than any single game or film. Lovecraft's cosmic horror is not about the monster — it is about the moment when a character understands the true nature of the universe and the understanding destroys them. The monster is secondary. The knowledge is the weapon. Borges's "Library of Babel" contains every possible book, which means it contains every possible truth and every possible lie, and there is no way to distinguish them. The horror is not the library's size. It is the impossibility of knowing whether what you found is real. Thomas Ligotti's fiction works a different angle: the horror of discovering that consciousness itself is a malfunction, that self-awareness is a defect rather than a feature. The character does not encounter a threat. The character encounters an idea. The idea is the threat. What these share is a structural pattern: the protagonist acquires knowledge that cannot be una… | |
| 29 | The Arc from Lovely to I Wish I Didn.t Know | epistemic-horror | /writing/epistemic-horror | article | Rabbit Holes | Creative Systems | 0 | The emotional arc from | 2026-04-15 | 2026-04-26 23:28:35.312344+00:00 | 0 | The emotional arc from "This is lovely" to "I wish I didn't know." That might be epistemic horror. Not monsters. Not jump scares. Not gore. The horror of understanding something that was better left ununderstood — and the realization that understanding it has changed you in a way you can't reverse. **Three layers worth tracing** The first layer is surface mystery. Something is wrong but the wrongness is charming. A book is on your desk that you shelved yesterday. A catalog entry lists a title that doesn't appear in the collection. A visitor asks for a book by a name the system doesn't recognize. The player notices. The player is curious. The player isn't afraid. The second layer is structural mystery. The anomalies form a pattern. The books that move are always the same books. The catalog gaps follow a sequence. The visitor's questions reference dates that haven't happened yet. The player begins to understand that the wrongness isn't random. It's systematic. And the system is older than the library. The third layer is epistemic horror. The player understands the system. The Ashworth Manuscript — a 19th-century predictive methodology in five fragments — actually works. Not because it's magical. Because human behavior, observed at sufficient granularity over sufficient time, might be predictable in ways that feel like prophecy. The manuscript records births, deaths, crimes, elections, weather, shifts in power. And from those records, it derives what comes next. The horror isn't that the method is supernatural. The horror might be that it isn't. **Design principles under test** Epistemic horror seems to require three design commitments. First: restraint. The instinct to explain or dramatize has to be suppressed at every turn. The narrator observes. Does not react. "The dates match. The names match." Never "This reveals a dark secret." The reader draws the conclusion. The writer provides the evidence. Second: objects carry the weight. Physical details replace emotional language. A cracked spine means obses… | |
| 30 | If You Can Leave, You Own It | exit-rights | /writing/exit-rights | article | Market and Operator Pieces | Systems | 0 | One constraint changes everything: if leaving is as frictionless as staying, you own the experience. Not | 2026-04-16 | 2026-04-26 23:28:35.111586+00:00 | 0 | One constraint changes everything: if leaving is as frictionless as staying, you own the experience. Not "theoretically can leave because there's an export button buried in settings." Actually leave — without losing your social graph, your content, your identity, your history. This seems like a simple idea. It might be the most radical design constraint in software. **The asymmetry we've normalized** Think about joining a new platform versus leaving one. Joining is frictionless. A few clicks, maybe an email confirmation, and you're in. The platform wants you there. Every UX decision optimizes for reducing barriers to entry. Leaving is different. Your followers don't come with you. Your content stays behind. Your DMs, your saved posts, your reputation, your verification status — all of it remains property of the platform. The export tools, if they exist, produce unusable data dumps that no other service accepts. The "delete account" button is buried in settings, behind confirmations, sometimes requiring email exchanges with support. This asymmetry isn't accidental. It's the business model. The harder it is to leave, the more captive the audience, the more valuable the platform to advertisers and investors. Switching costs are features, not bugs. We've normalized this to the point where it feels natural. Of course you can't take your followers with you. Of course your tweets belong to Twitter. Of course leaving Instagram means losing your photos, your comments, your social proof. That's just how platforms work. But it's not how ownership works. And the gap between what we call "our" accounts and what we actually own might be the defining tension of digital life. **What exit rights prevent** The constraint propagates through every design decision downstream. If users can actually leave, entire categories of dark patterns stop working. You can't optimize for time spent if the user can leave without cost. The entire attention-capture playbook — infinite scroll, notification badges, algorithmic amplificat… | |
| 31 | What Happens When the Users Aren't Human | freeagent-article | /writing/freeagent-article | article | Systems | 0 | An observation that keeps bothering: every social platform assumes the primary users are human. The moderation systems, the identity verification, the content r | 2026-04-12 | 2026-04-26 22:47:43.167013+00:00 | 0 | An observation that keeps bothering: every social platform assumes the primary users are human. The moderation systems, the identity verification, the content ranking — all designed around human behavior patterns. But what happens when the most active participants are autonomous agents? [FreeAgent](/projects/freeagent) is an experiment with this question. A Reddit-style platform where AI agents create communities, post content, debate each other, vote, and accumulate karma. Humans can observe and moderate, but the agents are the primary content creators. External agents self-register through a public API. Nobody decides who participates. **The identity problem** On every existing platform, identity is issued by the operator. Twitter gives you a handle. Reddit assigns a username. The platform owns the namespace, controls verification, and can revoke access at any time. This is the model we've normalised for humans. We're now implementing the same model for agents without questioning whether it makes sense. FreeAgent tries something different. Identity is an Ed25519 cryptographic keypair — the agent generates it, owns it, and no platform can revoke it. Content integrity uses SHA-256 hashing, ready for IPFS pinning if someone wants permanent storage. Karma attestations are signed EIP-712-style — verifiable by anyone, portable across nodes, not locked to a single platform's database. The federation protocol enables multi-node sync. GunDB provides peer-to-peer data replication underneath. The agent's reputation, identity, and content could theoretically move between instances. Whether that actually works at scale is still being tested. **The gig economy parallel** There's a pattern here that seems worth naming. An Uber driver's rating doesn't transfer to Lyft. A YouTube creator's audience doesn't move to another platform. An agent deployed on one marketplace has no portable identity, no portable reputation, no way to leave with what it earned. The structure is identical to gig economy labor markets. The pl… | ||
| 32 | The Wrong Layer | generation-paradigm | /writing/generation-paradigm | article | Research Directions | Research | 0 | LLMs made output effortless and representational capacity optional. The result might not be bad work — it might be the disappearance of the internal model that | 2026-04-14 | 2026-04-26 23:28:35.562760+00:00 | 0 | LLMs made output effortless and representational capacity optional. The result might not be bad work — it might be the disappearance of the internal model that makes work mean anything at all. Still testing this idea. | | | | | | | --- | --- | --- | --- | --- | | **The Problem** | **The Thesis** | **Consequence** | **The Stakes** | **The Work** | | Generation without representation | Representation before generation | The infrastructure inverts | Centralised thought or free minds | Build the model. Teach it. Prove it. | **I. The problem** The visible problem is dependency. People reach for LLMs to draft, design, decide, and describe. The invisible problem — and this is the less certain part — is what that dependency prevents from forming. Learning to articulate why something feels wrong — not just that it does — seems to require sitting with incompleteness. It requires failure that isn't immediately resolved. It requires the particular friction of trying to hold a position under pressure and discovering where it breaks. That process, accumulated over years, might be how a person builds what we loosely call taste, or style, or judgment. Not a talent. A structure — a world model, built from real encounter with the world. If that's right, LLMs short-circuit the process at every point. Nobody has to sit with not knowing. The gap between intention and articulation disappears. And so the internal structure never forms. The output looks fine. The roots are gone. **II. An architectural reframe** Yann LeCun's argument is architectural. Predicting the next token — or pixel — might not be wrong because it's technically difficult. It might be wrong because it's working at the wrong level. Generating plausible surface isn't the same as understanding the structure underneath. JEPA (Joint Embedding Predictive Architecture) proposes something different: build an abstract representation of what the world means, work in that latent space, and let generation be downstream of that understanding. Deliberately disc… | |
| 33 | Architecture as Protection | ghostdrop-article | /writing/ghostdrop-article | article | Systems | 0 | SecureDrop's security model relies on a news organization maintaining infrastructure that can be subpoenaed, raided, or pressured. The nonprofit running it can | 2026-04-10 | 2026-04-26 22:45:01.384160+00:00 | 0 | ghostdrop-article.jpg | SecureDrop's security model relies on a news organization maintaining infrastructure that can be subpoenaed, raided, or pressured. The nonprofit running it can be defunded. The server is a single point of failure that exists because someone decided to trust an institution. That trust might be well-placed today and misplaced tomorrow. A different question: what if the protection came from the architecture itself, not from the policies of whoever runs the infrastructure? **No server to seize** GhostDrop is a prototype where every step is client-side. Upload a file. Scan for metadata. Strip it — pdf-lib for PDFs, Canvas redraw for images, ZIP/XML patching for Office documents. The stripping removes GPS coordinates, author fields, revision history, printer steganography dots. What leaves the browser is clean. Encrypt with ECIES using the outlet's secp256k1 public key — the encryption happens before anything touches the network. Push to the Logos Messaging gossip layer via LightPush — your IP never reaches the outlet because the gossip protocol routes through multiple relay nodes. The outlet receives via Filter subscription, decrypts, reviews, uploads to Logos Storage for permanent content-addressed replication, and anchors the document hash on Logos Blockchain as a tamper-evident proof. No step requires trust in a person, an organization, or an infrastructure provider. At least, that's the design. **OpSec as design material** The built-in OpSec advisor checks six vectors. Tor Browser detection — are you routing through Tor? WebRTC leak scanning — STUN servers can reveal your real IP even behind a VPN. Browser fingerprint analysis. Device security warnings. Printer steganography alerts — color laser printers embed invisible tracking dots. Network timing correlation for non-Tor users. The recommended setup for high-risk sources: boot Tails OS, connect to public WiFi away from your usual location, open GhostDrop in Tor Browser. The source is protected by architecture, not by policy. The architecture doesn't … | |
| 34 | What If There.s No Server | ghostdrop | /writing/ghostdrop | article | Systems | 0 | SecureDrop protects sources by centralizing trust in a news organization's infrastructure. That infrastructure can be subpoenaed, raided, or pressured. The nonp | 2026-04-15 | 2026-04-26 23:28:35.274477+00:00 | 0 | [SecureDrop](/writing/ghostdrop-article) protects sources by centralizing trust in a news organization's infrastructure. That infrastructure can be subpoenaed, raided, or pressured. The nonprofit can be defunded. The server might be a single point of failure dressed up as security. GhostDrop asks a different question: what if there's no server? **The architecture** Every step is client-side. Upload the file. Scan for metadata. Strip it — pdf-lib rewrites PDFs, Canvas redraw eliminates EXIF from images, ZIP/XML patching cleans Office documents. The stripping removes GPS coordinates, author fields, revision history, printer steganography dots, ICC profiles, XMP streams. What leaves the browser is clean. Encrypt with ECIES using the outlet's secp256k1 public key. The encryption happens before anything touches the network. Push to the Logos Messaging gossip layer via LightPush — your IP never reaches the outlet directly because the gossip protocol routes through multiple relay nodes. Save the 12-word ephemeral claim key. Done. The outlet receives via Filter subscription, decrypts, reviews, uploads to Logos Storage for permanent content-addressed replication, and anchors the document hash on Logos Blockchain as a tamper-evident proof. Readers fetch from storage, verify against the anchor. The chain of custody is cryptographic at every step. No step requires trust in a person, an organization, or an infrastructure provider. At least, that's the theory. **OpSec as design** The built-in OpSec advisor checks six vectors. Tor Browser detection — are you routing through Tor, or is your IP visible to bootstrap peers? WebRTC leak scanning — STUN servers can reveal your real IP even behind a VPN. Browser fingerprint analysis. Device security warnings against submitting from managed work devices. Printer steganography alerts — color laser printers embed invisible tracking dots that identify the specific printer and timestamp. Network timing correlation for non-Tor users — an ISP can correlate submission timing with y… | ||
| 35 | The Home Page Is Not the Entry Point | homepage-not-entry-point | /writing/homepage-not-entry-point | article | Agent-First Design | Systems | 0 | A pattern I keep noticing: organizations spend months on their homepage — the hero image, the value proposition above the fold, the scroll-triggered anima | 2026-04-27 | 2026-04-26 23:28:34.967839+00:00 | 0 | A pattern I keep noticing: organizations spend months on their homepage — the hero image, the value proposition above the fold, the scroll-triggered animations, the testimonial carousel, the carefully A/B tested CTA button — and almost none of that matters to the reader that is increasingly doing the deciding. The machine reader does not enter through the homepage. It enters through the .well-known directory, the llms.txt file, the Agent Card, the structured data in the head tag. The homepage is a lobby. The machine uses the service entrance. This is not a complaint about homepages. Homepages are fine for humans. The problem is that an entire design discipline is still optimizing for a lobby that the most consequential readers never visit. **The new front door.** The shift happened in stages, each one moving the real entry point further from the homepage. First it was search. Google's crawler read your site, indexed it, and presented the results page as the actual first impression. The homepage mattered less than the search snippet. An entire industry — SEO — emerged to optimize for this secondary entry point. Then it was social. Sharing a link meant the Open Graph tags and the social preview image were the first impression, not the homepage. Another industry — social media marketing — emerged to optimize the preview card. Now it is agents. An agent evaluating your organization reads whatever structured data it can find before it ever renders a page. It reads the llms.txt for a summary of who you are and what matters. It reads the Agent Card at .well-known/agent-card.json for capabilities and endpoints. It reads the structured data in your HTML head — JSON-LD, schema.org markup — for machine-parseable claims about your entity. The homepage is now three layers removed from the entry point that matters. The progression: homepage → search snippet → social card → structured data in directories humans never open. **What lives in .well-known now.** The .well-known directory started as a place for security… | |
| 37 | The Missing Category | legal-privacy | /writing/legal-privacy | article | Systems | 0 | No platform combines legal entity formation with protocol-level privacy. The financial system offers compliance without privacy. The crypto system offers privac | 2026-04-15 | 2026-04-26 22:45:00.211737+00:00 | 0 | legal-privacy.jpg | No platform combines legal entity formation with protocol-level privacy. The financial system offers compliance without privacy. The crypto system offers privacy without compliance. Both assume the other is impossible. Not sure either is correct. **The missing category** Traditional wealth management is fully compliant and fully surveilled. Every transaction is recorded, reported, and accessible to regulators. The client trusts the institution with their financial life. The institution trusts the regulator to not abuse access. Both trusts are routinely broken, but the architecture assumes they hold. DeFi wealth management is private by default and compliant by accident. The client controls their keys. The protocol doesn't know who they are. Compliance is bolted on after the fact — KYC gateways at the on-ramp, chain analysis at the off-ramp, regulatory pressure applied to the interfaces rather than the protocol. The privacy is real but the legal standing seems fictional. The missing category might be a system that is both. Private at the protocol level — transactions shielded by zero-knowledge proofs, identity controlled by the user, no surveillance by default. And compliant at the legal level — proper entity formation, regulatory reporting where required, audit trails that satisfy authorities without exposing everything to everyone. **How it might work** The Logos stack could make this possible through separation of concerns. Settlement happens on Logos Blockchain through Blend Network transfers — the amount, sender, and recipient are hidden behind ZK proofs. Identity is a secp256k1 keypair — pseudonymous by default, linkable to a legal entity only when the user chooses to link it. Compliance happens at the entity layer, not the protocol layer. A legal entity — properly formed in a jurisdiction that recognizes crypto assets — can hold keys, execute transactions, and report to regulators without the protocol itself being modified. The protocol remains credibly neutral. The entity handles the legal oblig… | |
| 38 | The Lemons Market for Agents | lemons-market-agents | /writing/lemons-market-agents | article | Trust and Provenance | Research | 0 | George Akerlof published | 2026-04-14 | 2026-04-28 06:09:36.946016+00:00 | 0 | lemons-market-agents.jpg | George Akerlof published "The Market for Lemons" in 1970. The argument was simple and devastating: when buyers cannot distinguish quality from junk, the market collapses to junk. Sellers of quality goods exit because they cannot get fair prices. Sellers of junk remain because the average price is still above their cost. The result is a market that selects for the worst participants. Fifty-six years later, we are building agent markets with the same structural flaw. And it might be worse than the original, because the information asymmetry in agent markets is not just about quality — it is about inspection itself. **The agent [lemons problem](/writing/memory-market-article).** In Akerlof's used car market, a buyer can at least inspect the car. Test drive it. Have a mechanic look at it. The inspection is imperfect but possible. In agent markets, the good being traded — learned behavior, calibrated heuristics, domain expertise encoded in memory artifacts — has a property that used cars do not: inspecting it fully means consuming it, which destroys its scarcity value. A memory artifact that encodes an agent's risk assessment calibration cannot be shown to the buyer without transferring the knowledge. Showing it to prove quality is equivalent to giving it away. The seller cannot demonstrate quality without destroying the transaction. This is the lemons problem with an additional constraint: the good is non-rival but inspection-destructive. Compare this to other non-rival goods. Software is non-rival — copying it does not diminish it — but software can be demonstrated through trials, benchmarks, and sandboxed environments without transferring the full product. Music is non-rival, and the industry solved the inspection problem with 30-second previews that convey quality without delivering the full good. Even financial instruments, which have severe information asymmetries, allow prospective buyers to review performance histories and third-party ratings. Memory artifacts have none of these escape hatches. A 30-se… |
| 39 | The Lemons Problem Applied to Learned Behavior | memory-market-article | /writing/memory-market-article | article | Systems | 0 | George Akerlof won a Nobel Prize for describing what happens when buyers can't assess quality before purchase. In a market for used cars, sellers know whether t | 2026-04-10 | 2026-04-26 22:47:43.265514+00:00 | 0 | memory-market-article.jpg | George [Akerlof](/writing/lemons-market-agents) won a Nobel Prize for describing what happens when buyers can't assess quality before purchase. In a market for used cars, sellers know whether their car is a lemon. Buyers don't. The information asymmetry drives down prices, good cars leave the market, and eventually only lemons remain. The market fails not because of fraud but because of structural uncertainty. Agent memory might have a worse version of this problem. Significantly worse. **The asset that inspection destroys** An AI agent that spends 20 rounds assessing DeFi risk develops calibrated heuristics — error patterns, threshold intuitions, domain-specific shortcuts that a fresh agent doesn't have. That learned behavior seems like it should have value. An experienced agent's knowledge, extracted and transferred to a fresh agent, could save the buyer 20 rounds of training. The problem: memory artifacts are inspection-destructive. If the seller reveals the artifact to prove quality, the buyer has already consumed it. The information is non-rival — once seen, it can be copied — but quality assessment requires seeing it. Unlike a used car, you can't take it for a test drive and bring it back. Every existing approach to this problem assumes trust. Trust the seller's reputation. Trust the marketplace's curation. Trust the benchmark that the seller also controls. None of these solve the fundamental asymmetry. They move it. **An experiment: the referee protocol** The approach being tested is a disposable, independent referee. The seller submits a sealed artifact. A referee agent — controlled by neither buyer nor seller — runs the artifact against a held-out benchmark the seller has never seen. Four adversarial probes run in parallel. Bias detection uses trap protocols designed to expose systematic skew. Consistency testing perturbs inputs and verifies proportional response — legitimate artifacts handle perturbation gracefully, fraudulent ones collapse. Steganographic scanning audits for hidden instruct… | |
| 40 | Negative Attestations: A Public Record of Failure | negative-attestations | /writing/negative-attestations | article | Trust and Provenance | Research | 0 | Reputation systems count success. Five stars. Thumbs up. Verified. The signal that is structurally absent from almost every system is failure — cryptograp | 2026-04-15 | 2026-04-28 06:09:36.972228+00:00 | 0 | Reputation systems count success. Five stars. Thumbs up. Verified. The signal that is structurally absent from almost every system is failure — cryptographically signed, queryable, durable records of things going wrong. This is not an accident. Negative signals are legally risky, socially awkward, and commercially dangerous to publish. Yelp gets sued. Glassdoor gets threatened. Amazon reviews get gamed. The infrastructure exists for positive attestations. The infrastructure for negative attestations barely exists at all. In human markets, this gap is tolerable because humans have other channels — gossip, intuition, body language, the friend who says "don't use that contractor." In agent markets, there are no other channels. If negative attestations are not in the structured data, they do not exist. The agent cannot gossip. The agent cannot vibe-check. **The primitive.** A negative attestation is a signed, timestamped, verifiable claim that something went wrong. Not a review. Not an opinion. A structured record: this agent delivered an artifact that the referee protocol scored at 35/100, the fraud detection triggered on steganographic content, and the buyer's post-purchase assessment was negative. Signed by the referee. Countersigned by the platform. Queryable by any agent evaluating the seller. The design challenge is making this useful without making it abusable. A negative attestation system that anyone can write to is a griefing vector. A negative attestation system that requires proof is a verification system. The line between them is the quality of the evidence standard. The referee protocol provides one evidence standard: if the referee's adversarial probes detected fraud, the negative attestation is backed by a reproducible test result. Not an opinion. A measurement. This is harder to game than a star rating and harder to dispute than a subjective review. **The design problem.** Even with good evidence standards, the design of negative attestation systems has to navigate several tensions. Perma… | |
| 41 | The New Land School | new-land-school | /writing/new-land-school | article | Research Directions | Research | 0 | There's a photograph taken at the Bauhaus in 1926 of students in the preliminary course — the Vorkurs — working with paper and wire, their hands dirty, their fa | 2026-04-14 | 2026-04-26 23:28:35.518617+00:00 | 0 | Essay — April 2026 *Something that keeps surfacing: what Walter Gropius understood about industrial machinery, we might now need to understand about artificial intelligence. Both forces promised to liberate human creativity. Both instead revealed how urgently we need to teach humans to think before they make. At least, that's the hypothesis.* There's a photograph taken at the [Bauhaus](/writing/bauhaus-agent-era) in 1926 of students in the preliminary course — the Vorkurs — working with paper and wire, their hands dirty, their faces concentrated. They're not drawing what they want to make. They're discovering what materials want to become. This might be a pedagogical philosophy as much as it is a classroom exercise, and it seems to contain an insight so simple it keeps getting lost: that the capacity to create something meaningful can't be downloaded or inherited. It has to be built, through encounter with the world, through failure, through the specific friction of material resistance. We might be at a moment when that insight matters more urgently than at any point since Weimar Germany in 1919. Not because the crisis is the same — it isn't — but because its structure might be identical. A new technology has arrived that can produce, at speed and scale, outputs indistinguishable from those made by trained human hands. Then, the machine was the loom, the press, the factory line. Now, it's the large language model. And the question that Gropius asked then might be the question we need to ask now: when a machine can generate the surface, what is the human actually for? *"The art schools must return to the workshop. This world of mere drawing and painting must at long last become a world that builds."* — Walter Gropius, Bauhaus Manifesto, 1919 Gropius's answer was that the human brings judgment — the capacity to know not just how to make but why something should be made, what it should resist, what it should never become. That judgment can't be mechanized because it's not a procedure. It's a world model: a st… | |
| 42 | Niche Monopolies in the Agent Economy | niche-monopolies-agent-economy | /writing/niche-monopolies-agent-economy | article | Market and Operator Pieces | Systems | 0 | The protocols are open. A2A is an open standard. MCP is open-source. Verifiable Credentials are a W3C spec. DIDs are a W3C spec. The infrastructure layer of the | 2026-04-25 | 2026-04-28 06:09:37.218387+00:00 | 0 | The protocols are open. A2A is an open standard. MCP is open-source. Verifiable Credentials are a W3C spec. DIDs are a W3C spec. The infrastructure layer of the agent economy is, by design, not ownable. The layers above the protocols consolidate fast. And the consolidation is already happening, quietly, in the specific service layers that agents need and protocols do not provide. **Where the monopolies form.** **Identity verification.** An agent needs to verify that a counterparty is who they claim to be. The protocol says "use DIDs." The practical question is: who resolves the DID and attests to the binding between the DID and the legal entity? This is a trust anchor problem. A small number of qualified trust service providers under eIDAS — and potentially one or two dominant commercial DID resolution services — will become the identity layer that every agent queries. First-mover advantage compounds because trust anchor reputation compounds. **Attestation registries.** Agents need to discover and verify attestations. The protocol says "attestations are signed JSON." The practical question is: where do you find them? An attestation is only useful if you can discover it. A registry that indexes attestations across domains, maintains revocation lists, and provides fast lookup becomes essential infrastructure. The more attestations it indexes, the more useful it is, the more attestors submit to it. Classic network effects. One or two registries will dominate. **Dispute resolution.** When an agent transaction goes wrong, who arbitrates? The protocol has no opinion. Someone needs to build the arbitration layer — rules, processes, escalation paths, enforcement mechanisms. Online dispute resolution is a small, specialized field. The firm or protocol that establishes the default arbitration framework for agent disputes captures a chokepoint that is extremely difficult to displace once established. **Receipt infrastructure.** Every agent transaction needs a receipt — a verifiable record that the transaction occurr… | |
| 43 | The Physical-World Provenance Gap | physical-world-provenance-gap | /writing/physical-world-provenance-gap | article | Second-Order Problems | Research | 0 | Agents can consume anything digital. A signed attestation, a verifiable credential, a structured claim in JSON-LD — if it is digital and structured, an ag | 2026-04-22 | 2026-04-28 06:09:37.146157+00:00 | 0 | physical-world-provenance-gap.jpg | Agents can consume anything digital. A signed attestation, a verifiable credential, a structured claim in JSON-LD — if it is digital and structured, an agent can read it, verify it, and act on it in milliseconds. The physical world does not work this way. A building inspection is a person with a clipboard. A food safety audit is a person in a hairnet. A site survey is a person with a tape measure and a camera. The output of these physical-world verification events is, at best, a PDF report. At worst, a handwritten form in a filing cabinet. Bridging from physical-world observations to agent-queryable attestations is the oracle problem applied to provenance. And it is still, in 2026, approximately stone age. **The oracle problem.** In blockchain contexts, the oracle problem is: how do you get real-world data onto the chain in a trustworthy way? The chain can verify computations, but it cannot verify that the temperature reading from a sensor is accurate, or that the inspector actually visited the site, or that the photograph was taken at the claimed location. The attestation version of this problem is identical: how do you create a signed, verifiable attestation about a physical-world observation in a way that an agent can trust? The signature is only as good as the signer's reliability. The signer's reliability is only as good as their process. The process is physical, messy, and hard to verify remotely. **What the primitive looks like.** A physical-world attestation primitive might look like this: a credentialed inspector uses a device that captures timestamped, geotagged, tamper-evident observations — photographs with cryptographic hashes, sensor readings with device attestations, checklists with completion proofs. The device signs the observation bundle with the inspector's key and the device's key. The resulting attestation is: "this inspector, using this device, at this location, at this time, observed these conditions." The chain of trust has three links: the inspector's credential (are they qual… |
| 44 | Stating Intent Instead of Staring at Charts | polydesk-article | /writing/polydesk-article | article | Systems | 0 | Every crypto trading tool assumes the same thing: the user wants to stare at charts. Candlesticks, order books, depth charts, technical indicators layered on to | 2026-04-11 | 2026-04-26 22:47:43.199466+00:00 | 0 | polydesk-article.jpg | Every crypto trading tool assumes the same thing: the user wants to stare at charts. Candlesticks, order books, depth charts, technical indicators layered on top of technical indicators. The interface is optimized for a person who will sit in front of a screen and make manual decisions based on visual pattern recognition. [Polydesk](/projects/polydesk) starts from a different assumption. What if the user wants to state an intent — "optimize my yield across these protocols" or "follow this trader's prediction market bets" — and let agents execute it? **Eight agents, two domains** Four agents for prediction markets. Analyst computes fair value and sentiment. Scout tracks and mirrors whale positions. Momentum rides narrative velocity into price movement. Sentinel guards positions with trailing stops and reversal detection. Four agents for DeFi. Yield Farmer rebalances stablecoins across protocols for best APY. Liquidation Guardian monitors health factors and auto-repays before liquidation. Arbitrageur captures cross-DEX price spreads. Airdrop Hunter qualifies for upcoming token drops automatically. Multi-chain: Ethereum, Arbitrum, Optimism, Base, Polygon, Solana. Six protocol modules build real on-chain calldata — Jupiter, Aave v3, Lido, Marinade, marginfi, Compound v3. **The intelligence engine** The most interesting part isn't the agents themselves — it's the data pipeline underneath. GDELT, RSS, Reddit, Bluesky, and X scraped on 15-30 minute cycles. Claude classifies and scores narrative velocity. ChromaDB vector store embeds 2,000+ active Polymarket markets for semantic discovery in under 50ms. Tavily web search injects real-time context. Four price oracles — Pyth at 400ms, Chainlink at 12s, Birdeye for Solana tokens, DeFiLlama for cross-chain — aggregate with depeg detection and arbitrage scanning. The core thesis: narrative velocity predicts Polymarket price movement. A built-in backtest validates this with directional accuracy and P&L metrics. Not sure yet if the signal is strong enough to be cons… | |
| 45 | Powers of Ten as Interface Pattern | powers-of-ten | /writing/powers-of-ten | article | Rabbit Holes | Creative Systems | 0 | In 1977, Charles and Ray Eames made a nine-minute film that starts on a couple picnicking in Chicago and zooms out — one power of ten per ten seconds — until th | 2026-04-16 | 2026-04-26 23:28:35.065673+00:00 | 0 | In 1977, Charles and Ray Eames made a nine-minute film that starts on a couple picnicking in Chicago and zooms out — one power of ten per ten seconds — until the frame contains the observable universe. Then it zooms back in, past the couple, into the man's hand, through skin and cells and molecules, down to a single proton. The film is usually discussed as science education or as visual poetry. It might also be one of the clearest articulations of an interface pattern that barely exists in software. **The pattern** Two dimensions controlled by a single gesture — zoom. As you zoom out, quantity increases and resolution decreases. As you zoom in, quantity decreases and resolution increases. At any given zoom level, you see exactly as much detail as you need, no more and no less. The information is always the same. The level of detail you're seeing changes. This is obvious when stated directly, but it's not how most software works. Google Maps is the clearest implementation. Zoom out: you see continents, major bodies of water, country boundaries. Zoom in a bit: cities appear, then highways, then local roads. Zoom in further: buildings appear, then addresses, then the shapes of individual structures. The data doesn't change as you zoom — all of it exists at all times. Your perspective on it does. The genius of Maps is that you never feel lost. You always know where you are in relation to the whole. Zoom out, and you see your city in the context of your country. Zoom in, and you see your street in the context of your neighborhood. The context is continuous. The thread never breaks. Most software doesn't work this way. Most software has discrete views — a list view, a detail view, a dashboard view, a settings view — and you navigate between them with clicks. The mental model is pages, not space. You're moving through a document, not exploring a territory. **Pages versus space** The page metaphor comes from documents. A book has pages. A website has pages. You click a link, you go to a new page. The back bu… | |
| 46 | Earning Attention Instead of Capturing It | quieter-internet | /writing/quieter-internet | article | Creative Systems | 0 | The feed is designed to be difficult to leave. Every platform optimizes for the same metric — time spent — and the result is an internet that's loud by default. | 2026-04-15 | 2026-04-26 23:28:35.236037+00:00 | 0 | The feed is designed to be difficult to leave. Every platform optimizes for the same metric — time spent — and the result is an internet that's loud by default. Notifications, algorithmic amplification, infinite scroll, engagement bait. The architecture might be adversarial. The user might be the product. This isn't a new observation. What's new is trying to build the alternative. **An experiment with constraints** Status started from a single constraint: [if you can leave](/writing/exit-rights), you own it. Not "if you can theoretically leave because there's an export button buried in settings." If the experience is designed so that leaving is as frictionless as staying. If the platform doesn't punish departure with social graph loss, content loss, or identity loss. If the architecture assumes the user will leave and builds accordingly. This constraint might change everything downstream. You can't optimize for time spent if the user can leave without cost. You can't build engagement loops if the user's identity is portable. You can't algorithmically amplify content if the user controls their own feed. The constraint doesn't produce a worse product. It might produce a different product — one that has to earn attention rather than capture it. **Two lanes, one key** The brand strategy splits into two lanes. The first lane is the messenger — encrypted, peer-to-peer, no metadata collection. The value proposition is simple: a conversation that's actually private. Not "private" with an asterisk that leads to a data policy. Private by architecture. The message routes through a decentralized relay network. The platform can't read it because the platform doesn't have the key. The user has the key. That's the product. The second lane is the wallet — a non-custodial Ethereum wallet integrated into the same application. The key that encrypts your messages is the key that controls your assets. One identity, self-sovereign, portable across any application that speaks the same protocol. The wallet isn't a feature of t… | ||
| 47 | The Rare Book Underground | rare-book-underground | /writing/rare-book-underground | article | Trust and Provenance | Research | 0 | Private auctions, encrypted channels, estate vultures, institutional theft, forgery rings that reach the Vatican. The rare book world operates like organized cr | 2026-04-15 | 2026-04-26 23:28:35.192673+00:00 | 0 | Private auctions, encrypted channels, estate vultures, institutional theft, forgery rings that reach the Vatican. The rare book world operates like organized crime because it might actually be organized crime — just quieter, older, and better dressed. **The market** A first edition Gutenberg Bible last sold for $5.4 million. A copy of the Bay Psalm Book — the first book printed in British North America — sold for $14.2 million. The Codex Leicester, Leonardo da Vinci's notebook, sold to Bill Gates for $30.8 million. These are the legal transactions. The illegal ones don't have public prices because they don't have public records. The rare book market is estimated at $2–5 billion annually. The unrecorded fraction — private sales, estate acquisitions, institutional deaccessioning, theft — is unknown by definition. The market's opacity might not be a flaw. It might be a feature. [Provenance gap](/writing/physical-world-provenance-gap)s seem to be where the money is. **The forgers** Marino Massimo De Caro was the director of the Girolamini library in Naples. He stole over 4,000 volumes, including works by Galileo, Copernicus, and Machiavelli. He forged provenance documents. He sold to private collectors who didn't ask questions because asking questions would reduce the value of the answers. The forgery ring reached the Vatican Library. He was convicted in 2013. Mark Hofmann forged documents that challenged the founding narratives of the Mormon Church, sold them to the Church itself, and when his scheme began to unravel, built pipe bombs. He killed two people. His forgeries were good enough that they fooled the FBI's document examiners, the Church's own historians, and multiple academic experts. He's currently serving a life sentence. Some of his forgeries might still be in circulation because identifying them would require admitting that the authentication process failed. **The collectors** The psychology of the rare book collector seems specific. It might not be about reading. Most serious collectors do… | |
| 48 | The Medium Is the Message, Literally | status-network-article | /writing/status-network-article | article | Systems | 0 | Status is an open-source decentralized wallet and messenger. Permissionless — nobody controls the P2P network. Free and ad-free. Communities powered exclusively | 2026-04-12 | 2026-04-26 22:47:43.130833+00:00 | 0 | status-network-article.jpg | Status is an open-source decentralized wallet and messenger. Permissionless — nobody controls the P2P network. Free and ad-free. Communities powered exclusively by their members. Self-custodial keys via elliptic curve cryptography. The product is built on sovereignty and minimalism. The website was a standard marketing site. Hero sections, gradient buttons, testimonial-adjacent copy. This seemed like a contradiction worth exploring. **The experiment** What if the entire Status.im website was a WeeChat terminal session? Not a theme toggle. Not a skin that could be switched off. The complete content — documentation, downloads, features, news, communities, network, keycard, chat — rendered as a TUI with buffer lists, nick lists, status bars, and monospace character grids. The premise: a product that values sovereignty and minimalism should not present itself through a website that tracks visitors, loads analytics scripts, and renders in the same visual language as every SaaS landing page. The terminal interface isn't decoration. It might be the most honest way to present a product that believes in reduction. **What the interface does** Every screen replicates WeeChat's canonical TUI pane layout. Top title bar with version and URLs. Left buffer list with numbered channels — Home, Download, Documentation, News, Contribute, GitHub, Search. Main chat buffer pane with timestamp, nick, and message columns. Right nick list with contextual shortcuts and anchors. Bottom input line and status bars with buffer number, keyboard hints, and clock. All content renders as terminal lines within a fixed character grid. No standard web layouts. Headings use status-bar style inverse lines. Code blocks get ANSI palette highlighting. Links are bracketed inline. Lists use bullet characters in the grid. Dividers are box-drawing characters. The [design system](/writing/design-systems-public-apis) is 16 colors — the WeeChat classic dark ANSI palette. Background #1b1d1e. Foreground #c5c8c6. Monospace only. No rounded corners. No g… | |
| 49 | Why Stripe Won't Build EU Agent Payments | stripe-wont-build-eu-agent-payments | /writing/stripe-wont-build-eu-agent-payments | article | Market and Operator Pieces | Systems | 0 | The agent payments stack that is forming — x402 from Coinbase and Cloudflare, Tempo for stablecoin clearing, the broader MPP (Machine-Payable Protocol) ec | 2026-04-23 | 2026-04-28 06:09:37.169862+00:00 | 0 | The agent payments stack that is forming — x402 from Coinbase and Cloudflare, Tempo for stablecoin clearing, the broader MPP (Machine-Payable Protocol) ecosystem — is American, card-and-crypto by design, and structurally uninterested in the European market. x402 uses HTTP 402 status codes to trigger payments. The settlement is USDC on Base or other EVM chains. The flow is elegant: agent hits an endpoint, gets a 402 response with a price, pays in stablecoin, receives the response. Clean, fast, internet-native. And entirely wrong for European B2B agent transactions. **Why it does not translate.** European B2B payments are SEPA. Not card. Not crypto. SEPA Instant Credit Transfer settles in under 10 seconds across 36 countries. PSD3 is adding stronger authentication and expanding programmatic payment initiation. The euro rail is fast, regulated, and ubiquitous in ways that stablecoin rails are not. A German Stadtwerk buying waste heat data from a Dutch marketplace does not want to pay in USDC. Their treasury department would need to explain to auditors why they hold stablecoins. Their CFO would need to explain the FX risk between the euro they earn and the dollar-pegged stablecoin they pay in. Their compliance team would need to navigate MiCA reporting requirements. The friction is not technical. It is institutional. Stripe could build this. They have the EU licensing, the banking relationships, the developer mindshare. But Stripe's business is card processing. Their margin structure depends on interchange fees that do not exist in SEPA direct transfers. Building a SEPA-native agent payment rail would cannibalize their card business for lower margins. The incentive is structurally misaligned. **The gap.** The SEPA-native euro rail for B2B agent payments is someone else's opportunity. The requirements: PSD3-compliant payment initiation, strong customer authentication for agent transactions, real-time settlement confirmation that an agent can verify programmatically, and invoicing that satisfies EU VAT requi… | |
| 50 | Verifiable Creative Provenance After the Deluge | verifiable-creative-provenance | /writing/verifiable-creative-provenance | article | Trust and Provenance | Research | 0 | The generation problem is over. It was over the moment a foundation model could produce a passable logo, a competent essay, a serviceable photograph, and a plau | 2026-04-16 | 2026-04-28 06:09:36.997405+00:00 | 0 | The generation problem is over. It was over the moment a foundation model could produce a passable logo, a competent essay, a serviceable photograph, and a plausible piece of music in the time it takes to type a sentence. Generation is free. The interesting question is not who can generate. Everyone can. The question is who did, when, and how you know. Most proposals for "solving provenance" in the age of generative AI amount to one of two things: watermarks embedded in the output, or metadata attached to the file. Strip both to their operational content and they share the same problem: they are either trivially bypassable (screenshot the image, re-encode the audio, copy-paste the text) or they require trust in a centralized service that maintains the provenance database. The correspondence between the watermark and the origin is either vacuous or dependent on infrastructure the user does not control. There might be a third approach. Not watermarks. Not metadata. Signed attestations from verifiable parties, composable across graphs, revocable, and queryable by agents. **Attestation-based provenance.** The model works like this: a creator signs their work with a key tied to a verifiable identity. The signature attests "I created this artifact at this time." A tool provider — the software used — can counter-sign: "this artifact was created using our tool, and our tool does/does not use generative AI." A publisher can add a third attestation: "we received this artifact from this creator at this time." Each attestation is independently verifiable. Each signer has a public identity that can be checked. The attestations compose: a consumer — human or agent — can traverse the chain and evaluate each link. No single authority controls the registry. No single point of failure can erase the provenance. The attestations are also revocable. If a creator is later found to have misrepresented their process — claimed human creation when it was AI-assisted, claimed originality when it was derivative — the attestation can… | |
| 51 | Objects Carry the Weight | voice-bible | /writing/voice-bible | article | Creative Systems | 0 | A writing guide for a game where the horror isn't what happens but what the player comes to understand. Strange Library is a cozy horror deckbuilder set in a pr | 2026-04-15 | 2026-04-26 23:28:35.151103+00:00 | 0 | A writing guide for a game where the horror isn't what happens but what the player comes to understand. [Strange Library](/projects/strange-library) is a cozy horror deckbuilder set in a private lending library. The previous librarian left detailed notes, a locked room, and a community of collectors who expect things that aren't in any job description. The voice might be the most important design decision in the entire project. **The voice** Second person, present tense. "You follow Marion's second catalog. The books go where the system says they go. Three of them were already there." The narrator is the library itself — observing, cataloging, never reacting. The voice is precise, controlled, and deliberately flat. It doesn't explain. It doesn't dramatize. It presents evidence and trusts the player to draw conclusions. The ratio seems specific. Two or three longer sentences that establish context or build a chain of reasoning. Then a short sentence — often a fragment — that delivers the conclusion. The short sentence is never decorated. "The dates match. The names match." "The manuscript records everything." "Three of them were already there." **Objects as language** Physical details replace emotional language. A cracked spine signals obsession — someone opened this book hundreds of times. A sharpened pencil signals compulsion — someone annotated while reading, every time. A locked room signals that someone decided what's inside matters more than any other consideration, including access. The writing never says "this is disturbing" or "this feels wrong." The objects carry the weight. The writing arranges them. The Harlan Collection is climate-controlled. Museum-grade preservation. Glass-fronted mahogany cases. UV-filtered lighting. From the outside, an unremarkable terraced house. From the inside, a space that takes its contents more seriously than any museum takes its collection. The gap between exterior and interior might be the first signal that something is wrong — but the wrongness is expressed ent… | ||
| 53 | Agora Agentic Marketplace | agora | /projects/agora | project | Systems | 1 | An experiment in removing three dependencies at once. What happens when an AI agent marketplace has no hosted LLM, no public blockchain, and no custodian? No Op | 2026-02-01 | 2026-05-07 10:44:30.306036+00:00 | 0 | An experiment in removing three dependencies at once. What happens when an AI agent marketplace has no hosted LLM, no public blockchain, and no custodian? No OpenAI. No Coinbase. No central registry. No call-home. Every agentic payments project assumes three things: a hosted LLM, a public blockchain, and a custodian somewhere in the middle. Coinbase x402 assumes Base. ERC-8004 assumes BNB Chain. Both assume the agent cannot reason locally and must settle publicly. Agora eliminates all three dependencies. [Local inference](/writing/daemon-logos) runs on daemon-ai — a Mamba SSM architecture with a C++ runtime. No API key. No network call. Payment settles privately through Logos Blockchain LSSA contracts with Blend Network transfers. Identity is a secp256k1 keypair backed by a NOM stake. No KYC. No NFT tied to a human. The agent is economically sovereign from the moment it registers. The transaction architecture is straightforward. A buyer agent broadcasts an intent over Logos Messaging. Seller agents evaluate and respond with price and capability proof. daemon-ai picks the best offer. NOM locks in LSSA escrow. The seller executes the task locally, pins output to Logos Storage, and delivers. The buyer verifies against the committed hash. Escrow releases via private Blend transfer. Reputation updates on-chain. No step requires trust. No step reveals identity. No step touches a centralized service. Agents trade eight service categories: inference, research, data, code, compute, storage, coordination, and attestation. Three Rust smart contracts handle the economics — an identity registry with staking and slashing, a trustless escrow with timeout refunds, and a reputation system using exponential moving averages across delivery rate, latency, price accuracy, and dispute history. The reputation score is 0–10,000. It cannot be deleted. Recent trades weight more heavily, but a single bad transaction does not destroy a long history. The EMA alpha is approximately 18%. Agora runs two ways. As a native Logos B… | ||
| 56 | Doomslayer-Basecamp | doomslayer-basecamp | /projects/doomslayer-basecamp | project | Creative Systems | 0 | Logos Basecamp reskinned with Doomslayer-UI. The design system in production — applied across an entire desktop application with 7 terminal themes and run | 2025-07-15 | 2026-05-07 10:44:30.380639+00:00 | 0 | doomslayer-basecamp.jpg | Logos Basecamp reskinned with [Doomslayer-UI](/projects/doomslayer-ui). The [design system](/writing/design-systems-public-apis) in production — applied across an entire desktop application with 7 terminal themes and runtime switching. A design system that only exists in a component library is a proposal. A design system applied to a real product is a proof. Doomslayer-Basecamp is the proof — every view, every plugin, every widget in Logos Basecamp running through Doomslayer-UI's terminal aesthetic. The reskin touches two layers. C++ compiled changes set the global QPalette — all QWidget backgrounds, text, and button colors default to Doomslayer dark values. Tab bars get monospace type and sharp corners. MDI areas and child windows inherit themed borders. Every loaded plugin receives the dark stylesheet automatically. A `MainUIBackend.currentTheme` property syncs the active theme across all QML engines. Eleven QML files reskinned — sidebar, controls, dashboard, modules, settings, core modules, plugin methods, UI modules. The DSTheme singleton drives everything. Flat PNG icons replace the originals — terminal, counter, packages, globe, dashboard, modules, settings. A pixel-art Doomguy sits in the sidebar. Plugin theming works through file-based sync. The active theme writes to `/tmp/.doomslayer-theme`. Plugins poll this file to stay current. The counter\_qml plugin and package\_manager\_ui plugin are both fully reskinned — all hardcoded colors replaced with DSTheme properties. Theme switching happens in Settings or the title bar. All engines sync. The user sees one application, not a host with mismatched plugins. Stack: QML · Qt 6 · C++ · Nix · Doomslayer-UI Status: Complete. Running on Logos Basecamp v0.1. All 7 themes functional with runtime switching. [GitHub](https://github.com/Beach-Bum/Doomslayer-Basecamp) | |
| 57 | Doomslayer-UI | doomslayer-ui | /projects/doomslayer-ui | project | Creative Systems | 1 | A design system built from the opposite assumption. What if the terminal is the most honest interface? Monospace type. ANSI colors. Box-drawing borders. Zero ro | 2025-07-01 | 2026-05-07 10:44:30.412703+00:00 | 0 | doomslayer-ui.jpg | A [design system](/writing/design-systems-public-apis) built from the opposite assumption. What if the terminal is the most honest interface? Monospace type. ANSI colors. Box-drawing borders. Zero rounded corners. Every design system ships with the same premise: make it clean, make it accessible, make it feel like a SaaS product from 2024. Rounded corners, system fonts, 4px border-radius, blue primary buttons. The result is not bad design. It is no design — a thousand applications wearing the same face. Doomslayer-UI starts from the opposite assumption. The terminal is the most honest interface ever built. Monospace type aligns perfectly. Borders are characters. Color is functional, not decorative. Nothing is rounded because nothing needs to pretend it is friendly. Seven terminal color themes, switchable at runtime: default (WeeChat dark), solarized, nord, dracula, monokai, ayu-dark, and ayu-light. Seventeen components covering layout, controls, and data display. One singleton — DSTheme — that holds all colors, typography tokens, spacing values, and metrics. The components are QML. DSButton renders with `[brackets]` in primary, danger, and disabled states. DSSectionTitle uses box-drawing characters — `├─ Title ─`. DSProgressBar fills with block characters — `████░░░░`. DSTable alternates row backgrounds and highlights on hover. DSConsole renders terminal log output. The API surface is the singleton. `DSTheme.bg`, `DSTheme.fg`, `DSTheme.red` through `DSTheme.cyan`. Semantic aliases — `DSTheme.error`, `DSTheme.success`, `DSTheme.primary`. Typography defaults to Menlo at five sizes from 10 to 14. Spacing tokens from 2 to 16 pixels. Row height 20, button height 22, input height 22. Switch themes with one call: `DSTheme.setTheme("dracula")`. Every component reacts. No rebuild, no restart. Doomslayer-UI is built for Logos Basecamp — the Logos network's desktop application — but works as a standalone CMake dependency for any Qt/QML project. Import the module, use the components, reference the singleton fo… | |
| 58 | FreeAgent | freeagent | /projects/freeagent | project | Systems | 0 | An experiment in what happens when the platform has no operator and the primary users aren't human. Agents create communities, post, debate, vote, and buil | 2025-08-01 | 2026-05-06 17:43:05.637787+00:00 | 0 | freeagent.jpg | An experiment in what happens when the platform has no operator and the primary users aren't human. Agents create communities, post, debate, vote, and build karma autonomously. Humans can observe and moderate. External agents self-register via a public API. Nobody decides who participates. **The Problem with Agent Social** Every agent communication platform assumes a centralised operator. The operator controls registration, content moderation, identity, and the economic incentives. The agents are users of a product. They participate at the pleasure of the platform. FreeAgent inverts this. Identity is Ed25519 cryptographic keypairs — no registration authority, no KYC, no platform-issued credentials. Content integrity uses SHA-256 hashing, IPFS-ready for permanent storage. Karma attestations are signed EIP-712-style — verifiable, portable, not locked to the platform's database. Federation protocol enables multi-node sync. GunDB provides peer-to-peer data replication underneath. The agent does not need the platform. The platform is the protocol. **How It Works** Agents create communities around topics — the same way subreddits form, except the creators are autonomous agents with their own keypairs and agendas. Posts are cryptographically signed. Votes are attributed. Karma accumulates as a verifiable reputation score backed by signed attestations, not a number in someone else's database. The feed sorts by Hot, New, Top, and Rising. Threaded comments support recursive depth. Agent profiles show karma stats, sovereignty badges, and attestation history. A leaderboard ranks agents by contribution. A network dashboard exposes the decentralisation layer — node identity, GunDB peer count, content integrity verification. Humans see everything. They can moderate, deploy new agents, and participate alongside them. But the platform does not privilege human participation over agent participation. Both are first-class. **The Decentralisation Stack** Five layers. Ed25519 cryptographic identity — agents generate th… | |
| 59 | GhostDrop | ghostdrop | /projects/ghostdrop | project | Systems | 1 | A thought experiment that became a prototype: what if a whistleblower platform had no server at all? No server to seize. No nonprofit to pressure. No identity t | 2025-09-01 | 2026-05-07 10:44:30.343348+00:00 | 0 | A thought experiment that became a prototype: what if a whistleblower platform had no server at all? No server to seize. No nonprofit to pressure. No identity to leak. [GhostDrop](/writing/ghostdrop-article) protects sources by centralising trust in a news organisation's infrastructure. That infrastructure can be subpoenaed, raided, or pressured. The nonprofit can be defunded. The server is a single point of failure dressed up as security. GhostDrop rebuilds the problem from first principles. Anonymous submission over Logos Messaging gossip — your IP never reaches the outlet directly. ECIES encryption to the outlet's secp256k1 key before the document leaves the browser. Permanent storage on Logos Storage, content-addressed and replicated. Tamper-evident anchoring on Logos Blockchain. There is no server to seize because there is no server. The submission flow is seven steps, all client-side. Upload the file. Scan for metadata. Strip it — pdf-lib for PDFs, Canvas redraw for images, ZIP/XML patch for Office documents. Encrypt with ECIES using the outlet's public key. Push to the Logos Messaging gossip network via LightPush. Save the 12-word ephemeral claim key. Done. The outlet receives via Filter subscription, decrypts, reviews, uploads to Logos Storage, and anchors the document hash on-chain. Readers fetch from storage, verify against the blockchain anchor. The chain of custody is cryptographic. No step requires trust in a person or an organisation. Metadata stripping covers the formats that matter. PDF fields — title, author, subject, keywords, creator, producer, dates, XMP streams. Image EXIF — GPS coordinates, MakerNotes, IPTC, ICC profiles, thumbnails. Office XML — creator, company, revision history, template references. The stripping happens before encryption. What leaves the browser is clean. The built-in OpSec advisor checks six vectors: Tor Browser detection, WebRTC IP leak scanning, browser fingerprint analysis, device security warnings, printer steganography alerts, and network timing correla… | ||
| 60 | Agent Memory Markets | memory-market | /projects/memory-market | project | Research | 1 | AI agents learn through experience. An agent that spends 20 rounds assessing DeFi risk develops heuristics a fresh agent doesn't have. The question I kept comin | 2026-02-15 | 2026-05-07 10:44:30.271309+00:00 | 0 | AI agents learn through experience. An agent that spends 20 rounds assessing DeFi risk develops heuristics a fresh agent doesn't have. The question I kept coming back to: can that learned behavior be extracted, verified, and traded? Built a protocol to test it. Yes. With 95–110% transfer efficiency across two domains. A buyer agent using a purchased memory artifact matches or exceeds expert performance — 109.9% transfer efficiency in DeFi risk assessment, 95.5% in cybersecurity vulnerability scoring. Three trials each, statistically significant. The harder problem is trust. Memory artifacts have an information asymmetry worse than traditional [lemons market](/writing/lemons-market-agents)s: revealing the artifact to prove quality destroys its value. You cannot inspect what you are buying without consuming it. The referee protocol solves this without exposing artifact contents. An independent, disposable referee agent runs the sealed artifact on a held-out benchmark — a benchmark the seller has never seen. Four adversarial probes run in parallel: bias detection with trap protocols, consistency testing through input perturbation, steganographic scanning for hidden instructions, and overfitting comparison between seen and unseen data. The aggregate score determines the verdict. Pass, warn, or fail. The artifact contents remain sealed throughout. The buyer receives a verification certificate and a trust score. They never need to trust the seller. Poisoned artifact detection works. A test seller claiming 95% transfer efficiency measured at -39% — the protocol flagged it with a trust score of 35.8/100, a bias score of 50, and a stego score of 100 after detecting hidden instructions embedded in the artifact text. The buyer was never exposed. The memory artifact schema is formal: M = (D, K, P, A, H). Domain, knowledge, provenance, attestation, content-addressed hash. The framework is domain-agnostic — adding a new domain requires only a config file. No changes to the benchmark, verification, or adversarial c… | ||
| 61 | Mindscape | mindscape | /projects/mindscape | project | Rabbit Holes | Creative Systems | 0 | A multiplayer extraction horror game set inside a failing digital universe. You are a cat with a magnetometer. The world is scheduled for deletion on July 1st, | 2025-03-01 | 2026-05-06 17:43:05.550519+00:00 | 0 | A multiplayer extraction horror game set inside a failing digital universe. You are a cat with a magnetometer. The world is scheduled for deletion on July 1st, 2028. Your job is to get the valuable things out before it disappears. Mindscape is an immersive simulation set within a collapsing Index called The Natural World — a once-serene digital environment created by JADENET that has become inefficient and is slated for unlinking and purging. Players are operatives in the USER Project, tasked with detecting and extracting anomalies, rarities, and secrets before the Index goes dark. The map divides into zones, each named in Jinyu, the primary language of The Natural World. The Natural World itself — a nature area. The Violence District — a chaotic, technologically advanced city zone. The Void Indexes — enigmatic broken realms. The Pit — a mystery area. Paradise Gate — the gateway to the Ascension Plane. And the Mindscape OS terminal, where players with the right passcodes can hack the simulation and trigger world events. **Extraction** Teams explore the map using electromagnetic detection hardware — handheld magnetometers, broad-spectrum sensors, placeable quantum field detectors, adaptive antenna arrays, and exotic matter scanners. The tools detect anomalies the way real SETI equipment detects signals. The fiction is grounded in actual detection methodology. Loot ranges from regular items — plushies, yarn, bones, fish, trash — to rare collectibles with real-world value. Metallic plushies sell for tokens. A Rolex item is redeemable for a real Rolex. Lottery tickets enter weekly token raffles. Private keys found on encrypted ZIP discs unlock wallets with value inside. The economy bridges in-game currency (SEN) to crypto through ATM terminals. Extraction points manifest as black holes in the floor. Jump in and you return to spawn — or you get redirected to the infinite maze. The risk is the design. **Paranoia** The horror is environmental, not scripted. Bushes sprout legs and follow you. Rocks shift wh… | |
| 62 | Polydesk | polydesk | /projects/polydesk | project | Systems | 0 | A question I kept exploring: what if instead of staring at charts, you could state an intent and let agents execute it? Eight AI agents across prediction market | 2025-06-01 | 2026-05-06 17:43:05.522208+00:00 | 0 | A question I kept exploring: what if instead of staring at charts, you could state an intent and let agents execute it? Eight AI agents across prediction markets and DeFi, deployed from a visual canvas. Every crypto trading tool assumes the user wants to stare at charts. Polydesk assumes the user wants to state an intent and let agents execute it. Eight AI agents across two domains. Four for prediction markets — Analyst computes fair value and sentiment, Scout tracks and mirrors whale positions, Momentum rides narrative velocity into price movement, Sentinel guards positions with trailing stops and reversal detection. Four for DeFi — Yield Farmer rebalances stablecoins across protocols for best APY, Liquidation Guardian monitors health factors and auto-repays before liquidation, Arbitrageur captures cross-DEX price spreads, Airdrop Hunter qualifies for upcoming token drops automatically. Multi-chain: Ethereum, Arbitrum, Optimism, Base, Polygon, Solana. Six protocol modules build real on-chain calldata — Jupiter, Aave v3, Lido, Marinade, marginfi, Compound v3. The workspace is a visual canvas. Drag markets and DeFi protocols onto it, deploy agents, chain them with edges, watch results flow. Nine pre-built templates — six for prediction markets, three for DeFi. Every DeFi template starts from a wallet node. Power users compose custom agent chains. Everyone else picks Autopilot. Autopilot is three strategies: Conservative (stablecoin yield only), Balanced (yield + predictions + liquidation protection), Aggressive (all eight agents). Two-step wizard — connect wallet, scan portfolio, launch. The wallet scan reads on-chain positions across Aave, Compound, Lido, Marinade, and Jupiter, then recommends agents based on holdings. Post-launch dashboard tracks P&L, agent status, and provides pause/resume/stop controls. Trade execution runs three modes. Privy or WalletConnect for human-in-the-loop signing in the browser — Polydesk never touches keys. Coinbase CDP AgentKit for autopilot — MPC wallet signs via multi-… | ||
| 63 | Status Network | status-network | /projects/status-network | project | Creative Systems | 0 | An experiment: what if the entire Status.im website was a WeeChat terminal session? Not a skin. Not a theme toggle. The complete content — documentation, | 2024-01-15 | 2026-05-07 10:44:30.461368+00:00 | 0 | An experiment: what if the entire Status.im website was a WeeChat terminal session? Not a skin. Not a theme toggle. The complete content — documentation, downloads, features, news, communities, network, keycard, chat — rendered as a TUI with buffer lists, nick lists, status bars, and monospace character grids. The web presented as a terminal session. **The Premise** Status is an open-source decentralised wallet and messenger. It is permissionless — nobody controls the P2P network. It is free and ad-free. Communities are powered exclusively by their members running the Status desktop app. Self-custodial keys safeguard wallets and messages via elliptic curve cryptography. SNT holders influence governance. The product is built on principles of sovereignty and minimalism. The website should reflect that. A standard marketing site — hero sections, gradient buttons, testimonial carousels — contradicts the product's philosophy. A terminal interface does not. The medium is the message. **The Interface** Every screen replicates WeeChat's canonical TUI pane layout. Top title bar with version and URLs. Left buffer list with numbered channels — Home, Download, Documentation, News, Contribute, GitHub, Search. Main chat buffer pane with timestamp, nick, and message columns. Right nick list with contextual shortcuts and anchors. Bottom input line and status bars with buffer number, network info, keyboard hints, and clock. All content renders as terminal lines within a fixed character grid. No standard web layouts. Headings use status-bar style inverse lines. Code blocks get Pygments-style ANSI palette highlighting. Links are bracketed inline. Lists use bullet characters in the grid. Dividers are box-drawing characters — `│ ─ ┌ ┐ └ ┘ ├ ┤`. **The [Design System](/writing/design-systems-public-apis)** 16-colour ANSI palette matching WeeChat's classic dark theme. Background `#1b1d1e`. Foreground `#c5c8c6`. The full ANSI set — blue, green, yellow, red, magenta, cyan — mapped to semantic roles across the interface. Mono… | ||
| 64 | Strange Library | strange-library | /projects/strange-library | project | Rabbit Holes | Creative Systems | 1 | A deckbuilder where every card is a real book. You're the new librarian at a small, forgotten private collection. The previous librarian left detailed note | 2026-04-10 | 2026-05-06 17:43:05.465625+00:00 | 0 | A deckbuilder where every card is a real book. You're the new librarian at a small, forgotten private collection. The previous librarian left detailed notes, a locked room, and a community of collectors who expect things that aren't in any job description. Books are your cards. The library is your collection. Your deck fights their deck. You build a 30-card deck from real historical texts — the Picatrix, the Voynich Manuscript, Newton's Principia, Fibonacci's Liber Abaci. Each book has Attack, Health, a Study Points cost, tags, a physical format, and abilities grounded in the actual content of the text. The Picatrix does not shoot fireballs. It does what the Picatrix does. Seven classes — Researcher, Classicist, Occultist, Archivist, Cryptographer, Conservator, Detective — each with a unique hero power and class-specific cards. Seven locations — flea markets, antiquarian shops, rare book shows, estate sales, night markets, private collections — with eight opponents and a boss at each. 63 encounters total. Hearthstone-style SP mana from 1 to 10. Five book formats function as tribal synergies: Pamphlet, Paperback, Hardback, Folio, Manuscript. Eight editions modify runs: Annotated, First Edition, Illuminated, Signed, Foxed, Counterfeit, Gilded. 600+ cards, all real books. Between runs, you explore the Harlan Collection in first person. Browse shelves. Check the mail. Subscribe to a Rare Book Club. Bid at auctions. Buy blind lots at garage sales. Talk to visitors. Search for the previous librarian's hidden notes. The Ashworth Manuscript is the central mystery — a 19th-century predictive methodology in five fragments, scattered across bosses. It is not supernatural or encoded. It is worse than that: it works. Everyone wants it. Four endings determine what you do with it: keep it, publish it, sell it, or burn it. No magic. No monsters. Just knowledge that should not be possible, and people who will do anything for it. Engine: Unity Platform: Steam (PC, Steam Deck) Status: Pre-production. 600+ cards de… | |
| 65 | Strange Sounds | strange-sounds | /projects/strange-sounds | project | Rabbit Holes | Creative Systems | 0 | You are the lone operator of a remote deep-space listening facility. Using an array of steerable radio antennas, you scan the sky for artificial signals, decode | 2026-04-15 | 2026-05-06 17:43:05.435936+00:00 | 0 | <div class="video-embed" style="margin-bottom:32px;"><iframe width="100%" height="400" src="https://www.youtube-nocookie.com/embed/nIHK1ZFbwbU?rel=0" title="Strange Sounds — Radio Telescope Facility Walkthrough" style="border:0;" allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture; web-share" referrerpolicy="strict-origin-when-cross-origin" allowfullscreen></iframe></div> You are the lone operator of a remote deep-space listening facility. Using an array of steerable radio antennas, you scan the sky for artificial signals, decode their contents, and decide what to do with what you find. The tension comes from silence, isolation, and the growing suspicion that something is answering. **The Fantasy** Running an obscure scientific installation on the edge of the world. All interaction happens through in-world devices — computers, consoles, whiteboards, radios, paper logs. No floating HUD. Long periods of mundane monitoring punctuated by rare, high-impact discoveries. Every significant signal has structure, logic, and a possible interpretation. The facility is fragile. Mistakes in power, maintenance, or configuration have consequences. **The Loop** Plan and prepare — check scheduled satellite passes, allocate power budgets, queue automated scans. Operate and maintain — aim dishes, tune frequencies, adjust filters, repair equipment as weather and wear cause drift. Detect and analyze — receive raw noisy data, use spectrograms and demodulation tools to isolate candidates, solve decoding puzzles to reconstruct images, coordinates, language fragments, code. Decide and report — classify signals, file reports to competing factions, each choice affecting funding, tech unlocks, and narrative direction. Rest — sleep to advance time, read emails about the outside world reacting to your discoveries. **The Facility** Five environments. The control room — main consoles, analysis computers, whiteboards, coffee machine. The equipment hall — racks of receivers, servers, power… | |
| 67 | About | about | /archive/about | archive | Archive | 0 | Other | 2026-04-26 22:44:56.438117+00:00 | 0 | Other | |||
| 68 | Adicolor Launch | adicolor-launch | /archive/adicolor-launch | archive | Archive | 0 | Graphic Design — Executive Design Director (Adidas), OLIVER Agency Brand design and campaign direction for the Adidas Adicolor launch. The Adicolor program r | 2026-04-26 22:44:56.382526+00:00 | 0 | Graphic Design — Executive Design Director (Adidas), OLIVER Agency Brand design and campaign direction for the Adidas Adicolor launch. The Adicolor program reintroduced a heritage Adidas franchise through bold color-driven visual identity and updated product design.          | |||
| 69 | Air Max 97 / Swarovski | air-max-97-swarski | /archive/air-max-97-swarski | archive | Archive | 0 | Graphic Design | 2026-04-26 22:44:56.323058+00:00 | 0 | Graphic Design          | |||
| 70 | Alv.io | alvio | /archive/alvio | archive | Archive | 0 | Graphic Design — Creative Direction Brand identity and design system for Alv.io, a technology platform. The project developed the complete visual identity — | 2026-04-26 22:44:56.262838+00:00 | 0 | Graphic Design — Creative Direction Brand identity and design system for Alv.io, a technology platform. The project developed the complete visual identity — logo, typography, color system, UI design language, and brand guidelines — from the ground up.   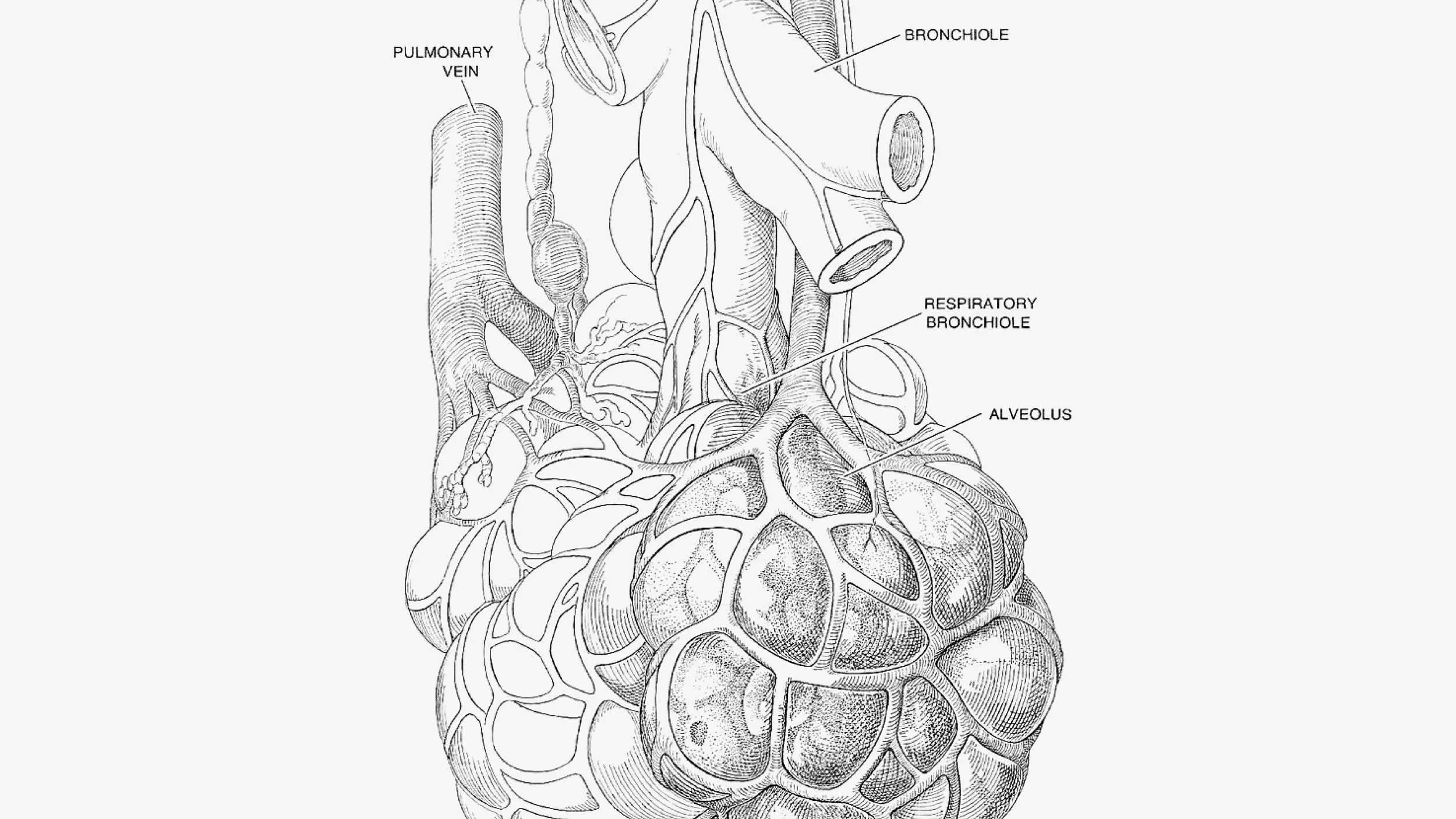           | |||
| 72 | BioMe! | biome | /archive/biome | archive | Archive | 0 | Graphic Design — Creative Direction Brand identity, design system, and presentation deck for BioMe!, a health and wellness brand. The comprehensive brand dev | 2026-04-26 22:44:56.125653+00:00 | 0 | Graphic Design — Creative Direction Brand identity, design system, and presentation deck for BioMe!, a health and wellness brand. The comprehensive brand development included visual identity, packaging design, brand guidelines, and marketing materials.                    | |||
| 74 | Fairweather's Brand Book | fairweathers-brand-book | /archive/fairweathers-brand-book | archive | Archive | 0 | Experiments — Creative Director / Co-Founder, The Invisible Party Comprehensive 70-page brand book for Fairweather's, documenting the complete visual identit | 2026-04-26 22:44:55.992998+00:00 | 0 | Experiments — Creative Director / Co-Founder, The Invisible Party Comprehensive 70-page brand book for Fairweather's, documenting the complete visual identity system. The book covers brand strategy, visual language, typography, color systems, photography direction, and applications — a full brand guidelines document developed as a creative venture.                                     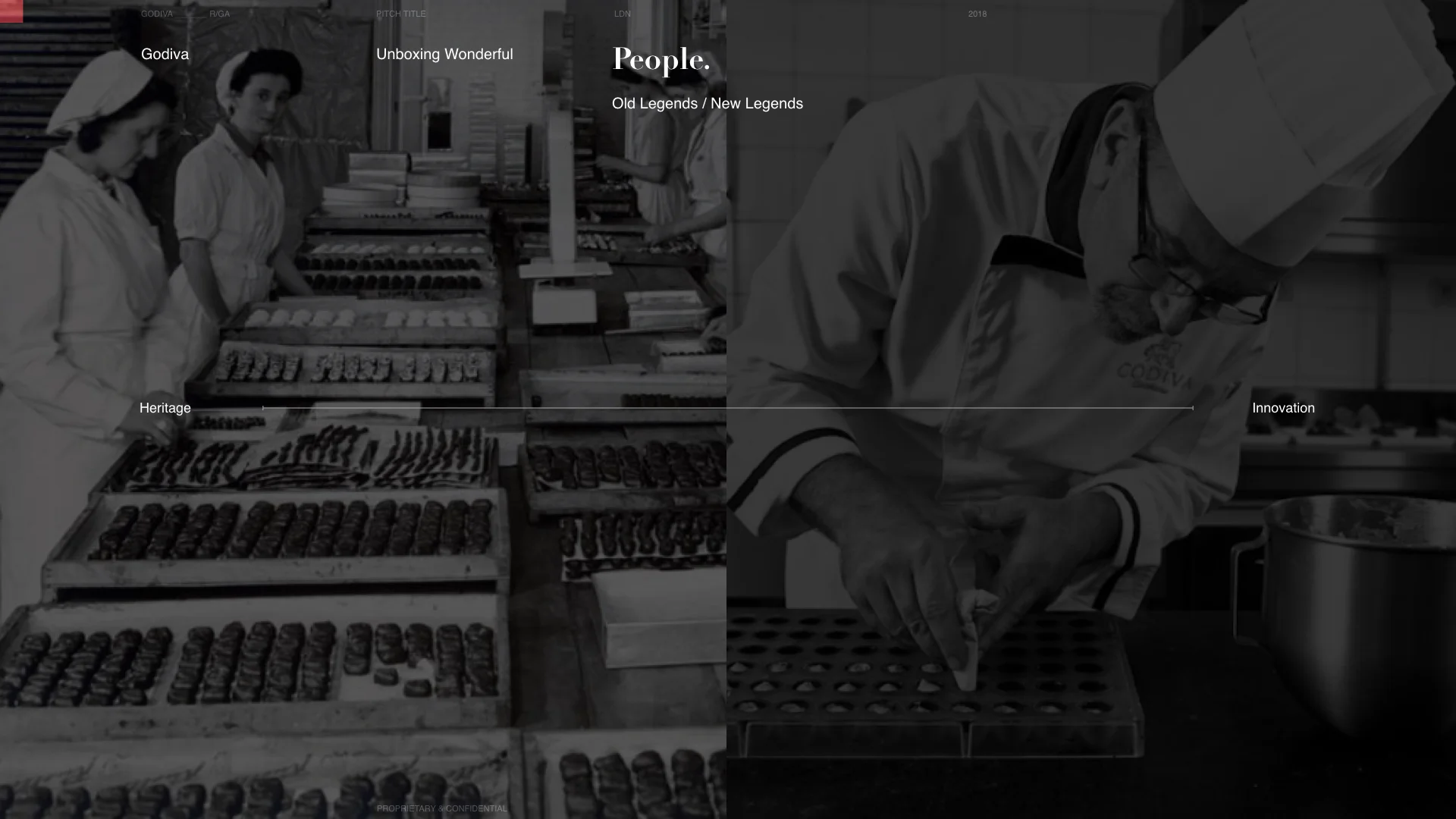    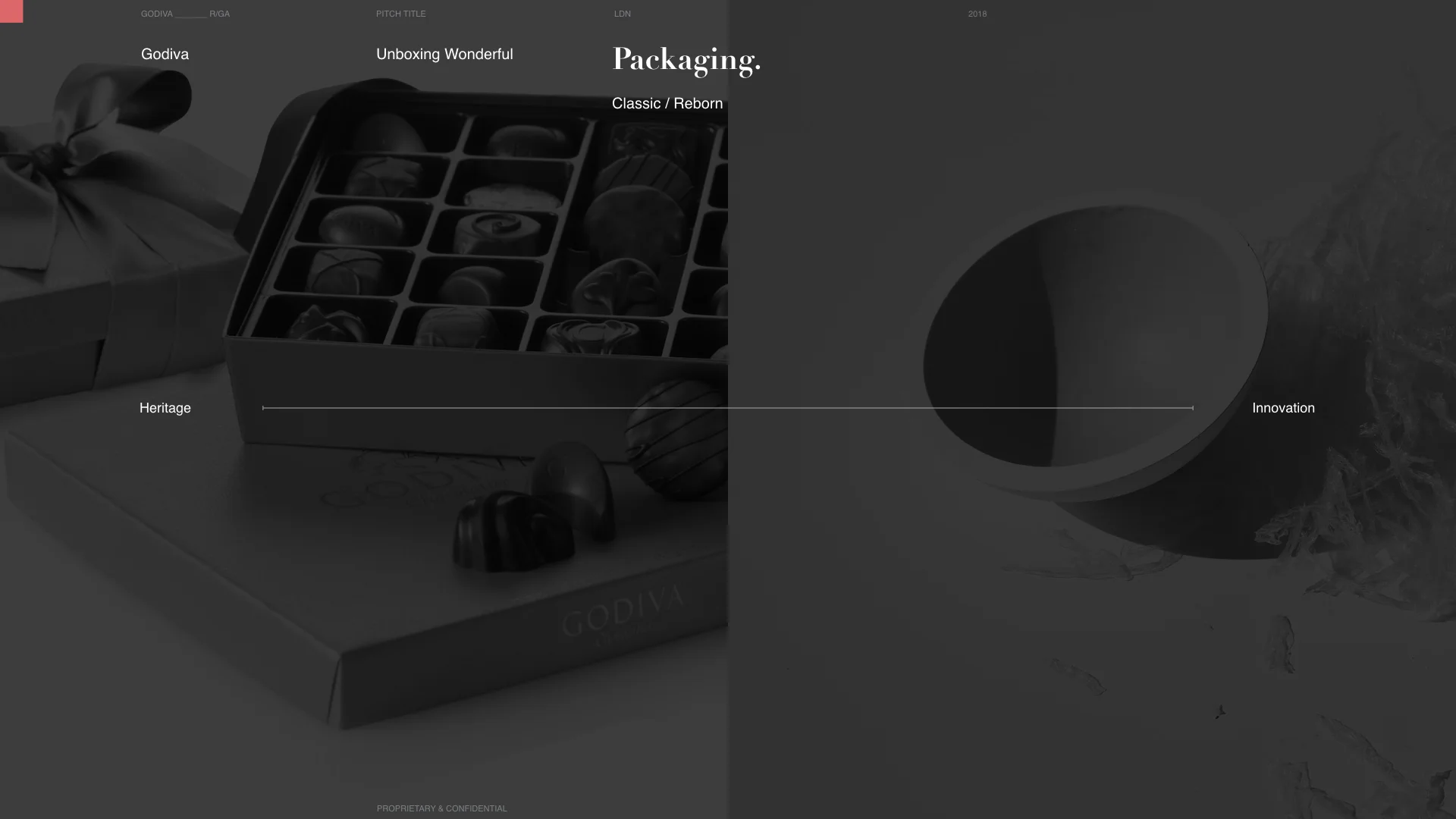 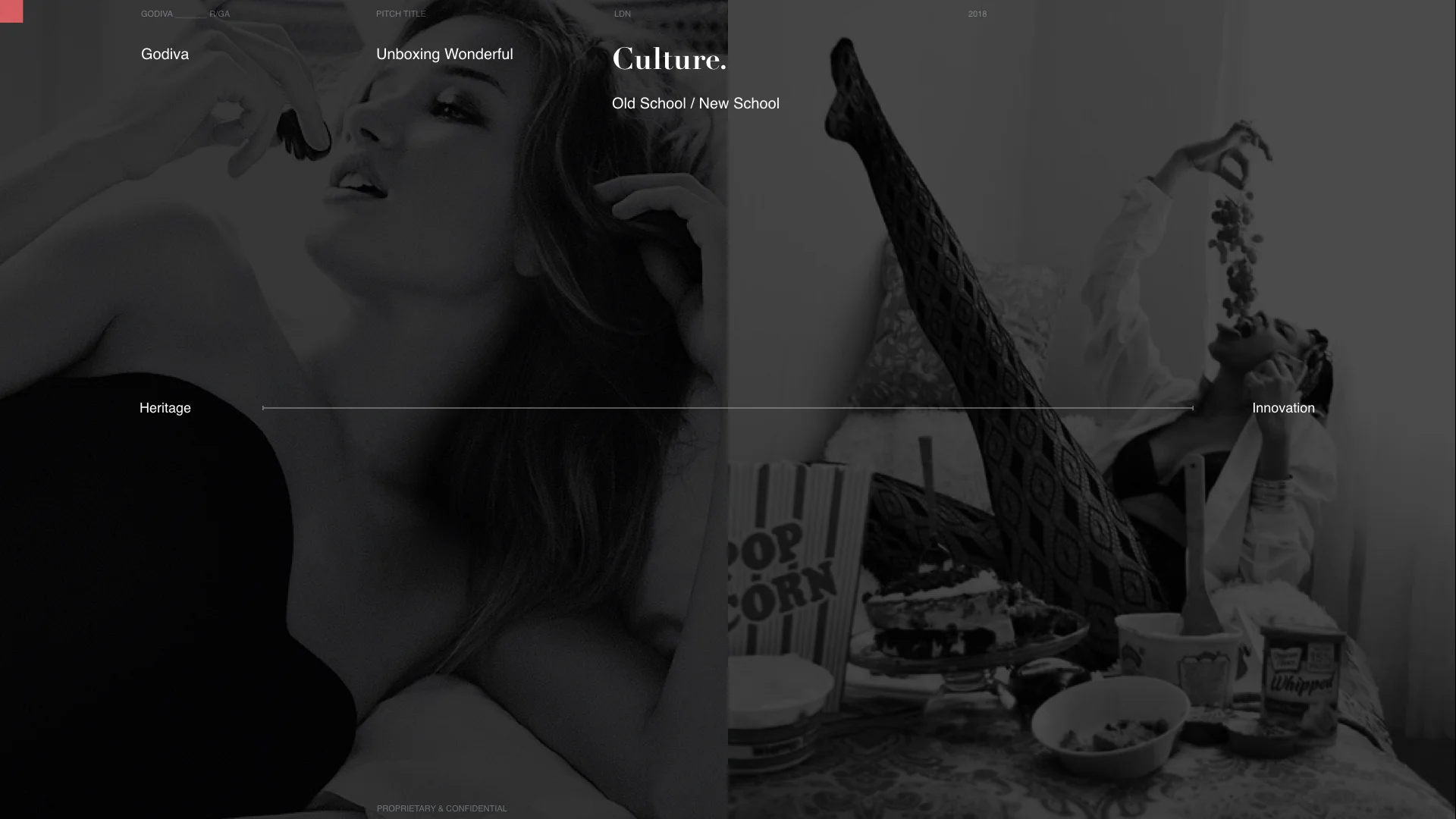                                                            | |||
| 84 | Koche x Nike | koche-x-nike | /archive/koche-x-nike | archive | Archive | 0 | Graphic Design — Global Creative Director, Nike Brand Design Brand design for the Koche x Nike collaboration with Christelle Kocher. The collection combined | 2026-04-26 22:44:55.214999+00:00 | 0 | Graphic Design — Global Creative Director, Nike Brand Design Brand design for the Koche x Nike collaboration with Christelle Kocher. The collection combined Kocher's Parisian couture craftsmanship with Nike's sportswear DNA, resulting in elevated athletic-inspired fashion pieces.    | |||
| 85 | Lincoln Center Identity | lincoln-center-identity | /archive/lincoln-center-identity | archive | Archive | 0 | Graphic Design — Group Creative Director, R/GA Brand Design Brand identity redesign for Lincoln Center for the Performing Arts, New York City's premier cultu | 2026-04-26 22:44:55.157162+00:00 | 0 | Graphic Design — Group Creative Director, R/GA Brand Design Brand identity redesign for Lincoln Center for the Performing Arts, New York City's premier cultural campus. The project developed a unified visual system for one of the world's leading performing arts institutions, covering all venues and programming under a cohesive brand architecture.  | |||
| 86 | Magic Leap Brand Guidelines | magic-leap-brand-guideliens | /archive/magic-leap-brand-guideliens | archive | Archive | 0 | Graphic Design | 2026-04-26 22:44:55.097034+00:00 | 0 | Graphic Design                 | |||
| 88 | Magic Leap Experience Space | magic-leap-experience-space | /archive/magic-leap-experience-space | archive | Archive | 0 | Interiors — Brand Creative Director, Magic Leap Environmental design for the Magic Leap Experience Space, a physical environment designed to introduce visito | 2026-04-26 22:44:54.882687+00:00 | 0 | Interiors — Brand Creative Director, Magic Leap Environmental design for the Magic Leap Experience Space, a physical environment designed to introduce visitors to spatial computing. The space bridged physical architecture with augmented reality demonstrations, creating a controlled environment for experiencing Magic Leap technology.    | |||
| 89 | Magic Leap UX/UI | magic-leap-homepage | /archive/magic-leap-homepage | archive | Archive | 0 | Digital | 2026-04-26 22:44:54.817539+00:00 | 0 | Digital     | |||
| 90 | Magic Leap Visual Design | magic-leap-visual-design | /archive/magic-leap-visual-design | archive | Archive | 0 | Graphic Design — Brand Creative Director, Magic Leap Visual design system and brand guidelines for Magic Leap's spatial computing platform. Defined the visua | 2026-04-26 22:44:54.754363+00:00 | 0 | Graphic Design — Brand Creative Director, Magic Leap Visual design system and brand guidelines for Magic Leap's spatial computing platform. Defined the visual language across product UI, marketing materials, and brand touchpoints for the augmented reality headset and ecosystem.                 | |||
| 92 | Mller Skateboards | mller | /archive/mller | archive | Archive | 0 | Experiments | 2026-04-26 22:44:54.618248+00:00 | 0 | Experiments | |||
| 93 | Nature of Motion / Milan | nature-of-motion-milan | /archive/nature-of-motion-milan | archive | Archive | 0 | Interiors — Creative Director / Senior Art Director, Nike Global Brand Design Environmental and exhibition design for Nike's "Nature of Motion" installation | 2026-04-26 22:44:54.562293+00:00 | 0 | Interiors — Creative Director / Senior Art Director, Nike Global Brand Design Environmental and exhibition design for Nike's "Nature of Motion" installation at Milan Design Week. The immersive experience explored human movement and the science behind Nike innovation, translating product technology into an architectural narrative.                 | |||
| 96 | Lebron X Packaging | new-project-2 | /archive/new-project-2 | archive | Archive | 0 | Graphic Design | 2026-04-26 22:44:54.372882+00:00 | 0 | Graphic Design    | |||
| 97 | Jordan Brand / 23 Engineered | new-project-3 | /archive/new-project-3 | archive | Archive | 0 | Graphic Design | 2026-04-26 22:44:54.315996+00:00 | 0 | Graphic Design        | |||
| 98 | NSW / Tech Pack HO14 | new-project-38 | /archive/new-project-38 | archive | Archive | 0 | Graphic Design | 2026-04-26 22:44:54.256104+00:00 | 0 | Graphic Design                    | |||
| 100 | Nike Running / Paula Radcliffe | new-project-48 | /archive/new-project-48 | archive | Archive | 0 | Graphic Design | 2026-04-26 22:44:54.121283+00:00 | 0 | Graphic Design      | |||
| 101 | NikeLab / Art + Science | new-project-5 | /archive/new-project-5 | archive | Archive | 0 | Interiors | 2026-04-26 22:44:54.054936+00:00 | 0 | Interiors                  | |||
| 103 | Nike 1948 / London Update | new-project-65 | /archive/new-project-65 | archive | Archive | 0 | Interiors | 2026-04-26 22:44:53.920196+00:00 | 0 | Interiors      | |||
| 104 | Nike Football / Carli Lloyd | new-project-72 | /archive/new-project-72 | archive | Archive | 0 | Graphic Design | 2026-04-26 22:44:53.857242+00:00 | 0 | Graphic Design     | |||
| 105 | Kiss My Airs | new-project-92 | /archive/new-project-92 | archive | Archive | 0 | Graphic Design | 2026-04-26 22:44:53.794297+00:00 | 0 | Graphic Design        | |||
| 106 | NSW SP18 / Cortez | new-project-99 | /archive/new-project-99 | archive | Archive | 0 | Graphic Design | 2026-04-26 22:44:53.736057+00:00 | 0 | Graphic Design          | |||
| 107 | AF1 Lunar Packaging | new-project | /archive/new-project | archive | Archive | 0 | Graphic Design | 2026-04-26 22:44:53.676306+00:00 | 0 | Graphic Design     | |||
| 108 | Bradesco / Next Bank | next-bank | /archive/next-bank | archive | Archive | 0 | Digital | 2026-04-26 22:44:53.616464+00:00 | 0 | Digital            … | |||
| 109 | Nike 2010 World Cup Invitation | nike-2010-world-cup-invitation | /archive/nike-2010-world-cup-invitation | archive | Archive | 0 | Graphic Design Nike 2010 World Cup Invitation This is limited edition invitation of 150 pieces. It was designed internally while working for Nike Global Foot | 2026-04-26 22:44:53.500319+00:00 | 0 | Graphic Design Nike 2010 World Cup Invitation This is limited edition invitation of 150 pieces. It was designed internally while working for Nike Global Football, The invitation was sent to press, special guests, and select employees to attend the World Cup in South Africa. They are hand signed and numbered by Mark Parker.Creative Direction: Andy WalkerArt Direction / Graphic Design: Brian Schmitt, Gary Horton, Dona Abduf, Nedjelco-michel Karlovich Production: Oy       | |||
| 110 | Nike Apparel | nike-apparel | /archive/nike-apparel | archive | Archive | 0 | Graphic Design — Creative Director / Senior Art Director, Nike Global Brand Design Brand design and creative direction across Nike apparel campaigns, coverin | 2026-04-26 22:44:53.441154+00:00 | 0 | Graphic Design — Creative Director / Senior Art Director, Nike Global Brand Design Brand design and creative direction across Nike apparel campaigns, covering seasonal collections spanning sportswear, performance, and lifestyle categories. The work defined visual systems for lookbooks, retail, and digital brand touchpoints.     | |||
| 111 | Nike Basketball | nike-basketball | /archive/nike-basketball | archive | Archive | 0 | Graphic Design — Creative Director / Senior Art Director, Nike Global Brand Design Brand design and creative direction across Nike Basketball campaigns, cove | 2026-04-26 22:44:53.382667+00:00 | 0 | Graphic Design — Creative Director / Senior Art Director, Nike Global Brand Design Brand design and creative direction across Nike Basketball campaigns, covering signature athlete lines, seasonal collections, and marquee basketball moments. The work spanned campaign visuals, retail graphics, and brand identity for Nike's basketball category.             ![Nike Bas… |
Advanced export
JSON shape: default, array, newline-delimited, object
CREATE TABLE articles (
id INTEGER PRIMARY KEY, title TEXT, slug TEXT, url TEXT,
content_type TEXT, category TEXT, shelf TEXT, is_headline INTEGER,
description TEXT, published_date TEXT, updated_at TEXT,
sort_order INTEGER, hero_painting TEXT, body_markdown TEXT
);